I finally managed to train my network to learn the XOR function exactly, with MSE = 0, using ReLU activation. However, coffee spilled on the paper where I had written the weights, and I lost one of them. Can you help me find the missing weight?
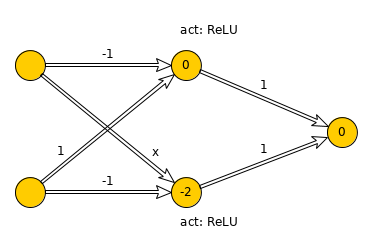
I finally managed to train my network to learn the XOR function exactly, with MSE = 0, using ReLU activation. However, coffee spilled on the paper where I had written the weights, and I lost one of them. Can you help me find the missing weight?
A.:
For input (1, 0), we see that the top activation is zero, and therefore the bottom activation must be 1. However, the bottom activation is max(0, x-2), so x has to be 3.