|
MC102 |
| ENTRADA E SAÍDA |
Já vimos como escrever, com write e writeln, e como ler uma entrada, com read e readln. Mas, como lemos mais de uma entrada por vez, sem usarmos vários reads ou readlns?
PROGRAM P;
VAR i1,i2:integer;
BEGIN
read(i1, i2); {lê dois inteiros}
END.
|
Só que para que isso funcione, o usuário deve separar os dois inteiros com um ou mais espaços. Veja algumas entradas válidas:
2 3 2 -3 -2 2 -2 -2 etc |
Da mesma forma, podemos ler outros tipos:
PROGRAM P;
VAR r1,r2:real;
b1,b2:boolean;
BEGIN
read(r1, r2); {lê dois reais}
read(b1, b2); {lê dois booleanos}
END.
|
Algumas entradas válidas são:
2.3e22 2.345E2 true false -2.3e22 2.45E-2 false true 0.4 -3.980 false false 0.498e-2 12.3 true true etc |
Em suma, o read lê de forma diferente os diferentes tipos de entrada (tipo este determinado pela variável que é passada como parâmetro para o read, que receberá a entrada):
| CARACTERES |
Em Pascal, caracteres são guardados em um tipo de variável especial, declarada assim:
VAR ch : char; |
Aqui, ch é do tipo caracter, o que significa que pode guardar qualquer caracter (mas apenas um), quer seja, letra, número, sinais gráficos etc.
Mas, e como armazenamos caracteres nessas variáveis?
ch := 'a';
ch := 'A';
ch := ' '; {espaço}
ch := '"'; {aspas duplas}
|
Note que 'a' é diferente de 'A', ou seja, há distinção entre caracteres maiúsculos e minúsculos.
Um outro ponto interessante é que caracteres são ordenados e seqüenciais:
'A' < 'B' < 'C' < ... < 'Z' 'a' < 'b' < 'c' < ... < 'z' '0' < '1' < '2' < ... < '9' |
Não confunda 9 com '9', o primeiro é um número e o segundo um caracter.
Então podemos fazer:
FOR ch:='A' TO 'Z' DO write(ch); |
e teremos o alfabeto.
| LENDO E ESCREVENDO CARACTERES |
Para ler um único caracter, fazemos:
read(ch); |
onde ch é do tipo char. Já para escrever:
write(ch); |
Isso é muito útil na interação com o usuário, por exemplo:
ch := 's';
WHILE (ch<>'n') AND (ch<>'N') DO
BEGIN
faz algo
write('quer continuar? (s/n) ');
readln(ch)
END;
|
ou
REPEAT
faz algo
write('quer continuar? (s/n) ');
readln(ch)
UNTIL (ch='n') OR (ch='N');
|
Novamente, como o usuário pode entrar tanto com 'n' quanto com 'N', e como 'n' ≠ 'N', devo testar os dois.
Agora suponha que temos a seguinte entrada:
Esta é uma frase . |
e queremos gerar a saída:
Esta é uma frase |
Ou seja, pegamos uma frase que termina com '.' e separamos as palavras dela. Como faremos?
enquanto for diferente de '.' (senão acabou a frase)
enquanto for diferente de ' ' (senão ainda é a palavra)
leio uma letra
escrevo essa letra
dou nova linha
|
ou
repito
enquanto for diferente de ' '
leio uma letra
escrevo a letra lida
dou nova linha
até que encontre um '.'
|
mas isso tem um problema, ' ' será lido e escrito. Quero testar antes de escrever, então ler tem que ser a última coisa a fazer:
leio uma letra
enquanto for diferente de '.' (senão acabou a frase)
enquanto for diferente de ' ' (senão ainda é a palavra)
escrevo a letra lida
leio uma letra
dou nova linha
|
mas isso também tem um problema: repare que, se lemos um ' ', entraremos num laço infinito (confira!). Então, para corrigir, devemos fazer:
leio uma letra
enquanto for diferente de '.' (senão acabou a frase)
enquanto for diferente de ' ' (senão ainda é a palavra)
escrevo a letra lida
leio uma letra
dou nova linha
leio uma letra
|
Pronto! Como fica isso em Pascal?
read(ch);
WHILE ch<>'.' DO
BEGIN
WHILE ch<>' ' DO
BEGIN
write(ch);
read(ch)
END
writeln;
read(ch)
END;
|
Mas, em vez de 2 WHILEs, não poderíamos por tudo em um só? Claro, mas teríamos que mudar o código, se fizermos somente:
enquanto for direrente de '.' e diferente de ' ' faça |
o programa pararia no primeiro espaço, o que não queremos. Então, como fazemos?
read(ch);
WHILE ch<>'.' DO
IF ch<>' ' THEN
BEGIN
write(ch);
read(ch)
END
ELSE BEGIN {é = ' '}
read(ch);
writeln
END
END;
|
Agora, qual o maior problema com esse código? O read exige
ch := readkey; |
readkey espera que o usuário digite algo e, assim que ele digitar, pega o caracter que ele digitou. Então não preciso do
Legal, não? Mas como nem tudo é uma maravilha, há um detalhe sobre o readkey: como o nome diz, ele lê uma tecla somente. Você não consegue ler integer, real ou palavras com ele, somente char. Outra coisa, enquanto que com read você escreve, vê o que escreveu na tela e então dá enter, com readkey isso não acontece. Ao você digitar algo, readkey lê diretametne a tecla, sem mostrar o que você digitou na tela. Se você quiser que mostre, terá que ecoar o caracter lido, ou seja, escrevê-lo na tela, com write.
Então o programa fica:
ch := readkey;
WHILE ch<>'.' DO
BEGIN
WHILE ch<>' ' DO
BEGIN
write(ch);
ch := readkey
END
writeln;
ch := readkey
END;
|
| CARACTERES E A TABELA ASCII |
Até agora vimos como usar caracteres, mas como será que o computador entende caracteres? Bem, ele não entende. Quando você digita um caracter, o Sistema Operacional se encarrega de traduzí-lo para um código numérico que ele possa manipular mais tarde. Assim, os caracteres nada mais são do que números. Mas como ele faz essa tradução?
Para fazer a tradução de caracteres em números, o Sistema Operacional usa uma tabela, chamada ASCII (veja no próximo tópico). Existem vários tipos de tabela, dependendo do computador que é usado e do país em que é usado, apesar disso, ela não muda dos números 0 ao 127.
Mas você não precisa decorar essa tabela para brincar com caracteres. O Pascal tem duas funções para lidar com caracteres:
VAR n : integer;
c : char;
BEGIN
n := Ord('a'); {n recebe o código ascii de 'a'}
c := 'z';
n := Ord(c); {n recebe o código ascii do caracter armazenado em c, ou seja, 'z'}
c := Chr(120); {c recebe 'x' (veja tabela abaixo)}
c := Chr(Ord('z')); {c recebe 'z'}
END.
|
Assim, Ord recebe um caracter e retorna o código ascii deste, e Chr recebe um código ascii e retorna o caracter correspondente a este.
Mas para que podemos usar isso? Vejamos alguns exemplos:
Exemplo 1: Uma codificação simples.
Suponha que queremos codificar uma determinada frase de 10 letras digitada, para isso, lemos cada caracter e somamos 5 ao seu ascii, resultando num caracter diferente:
PROGRAM codifica;
VAR n : integer; {ascii de c1}
c1 : char; {caracter digitado}
c2 : char; {caracter codificado}
i : integer; {contador do FOR}
BEGIN
FOR i:=1 TO 10 DO
BEGIN
c1 := readkey; {leio o caracter digitado}
n := Ord(c1); {pego o ascii do caracter digitado}
n := n + 5; {incrementei o código em 5}
c2 := Chr(n); {pego o caracter desse novo código}
write(c2) {escrevo o caracter codificado}
END
END.
|
Exemplo 2: Transformar minúsculas em maiúsculas e vice-versa.
Nesse caso, o Pascal já tem uma função pré-definida
ch1 := Uppercase(ch2); |
para transformar minúsculas (ch2) em maiúsculas (ch1), apesar disso, não tem uma função para transformar maiúsculas em minúsculas. Então vamos construir a nossa função
Para tal, precisamos de algumas informações:
PROGRAM transforma;
VAR l : char; {a letra a ser transformada}
{recebe c por referência, e o substitui pela sua maiúscula}
PROCEDURE Maiuscula(VAR c : char);
VAR mai : integer; {guarda o ascii da maiúscula}
BEGIN
IF (c>='a') AND (c<='z') THEN {c é minúscula}
BEGIN
mai := Ord(c) - Ord('a') + Ord('A');
c := Chr(mai)
END
{se não for minúscula (ou mesmo não for letra), deixa como está}
END;
{recebe c por referência, e o substitui pela sua minúscula}
PROCEDURE Minuscula(VAR c : char);
VAR mai : integer; {guarda o ascii da maiúscula}
BEGIN
IF (c>='A') AND (c<='Z') THEN {c é maiúscula}
BEGIN
mai := Ord(c) - Ord('A') + Ord('a');
c := Chr(mai)
END
{se não for maiúscula (ou mesmo não for letra), deixa como está}
END;
BEGIN
l := 'd';
Minuscula(l);
writeln(l); {escreve 'd', não alterou}
Maiuscula(l);
writeln(l); {escreve 'D', a maiúscula}
l := 'P';
Maiuscula(l);
writeln(l); {escreve 'P', não alterou}
Minuscula(l);
writeln(l) {escreve 'p', a minúscula}
END.
|
note que o procedimento "Maiuscula" poderia ser tão somente:
{recebe c por referência, e o substitui pela maiúscula dela}
PROCEDURE Maiuscula(VAR c : char);
BEGIN
IF (c>='a') AND (c<='z') THEN {c é minúscula}
c := Chr(Ord(c) - Ord('a') + Ord('A'))
{se não for minúscula (ou mesmo não for letra), deixa como está}
END;
|
mas fizemos mais longo para ficar mais legível a operação.
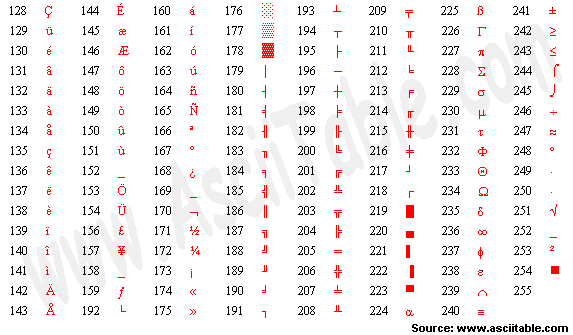
| TABELA ASCII |
Essa é a tabela usada em linux (ISO 8859-1):
Dec Char Dec Char Dec Char Dec Char
-------------------------------------------------------------------------
0 NUL '\0' 32 SPACE 64 @ 96 `
1 SOH 33 ! 65 A 97 a
2 STX 34 " 66 B 98 b
3 ETX 35 # 67 C 99 c
4 EOT 36 $ 68 D 100 d
5 ENQ 37 % 69 E 101 e
6 ACK 38 & 70 F 102 f
7 BEL '\a' 39 ' 71 G 103 g
8 BS '\b' 40 ( 72 H 104 h
9 HT '\t' 41 ) 73 I 105 i
10 LF '\n' 42 * 74 J 106 j
11 VT '\v' 43 + 75 K 107 k
12 FF '\f' 44 , 76 L 108 l
13 CR '\r' 45 - 77 M 109 m
14 SO 46 . 78 N 110 n
15 SI 47 / 79 O 111 o
16 DLE 48 0 80 P 112 p
17 DC1 49 1 81 Q 113 q
18 DC2 50 2 82 R 114 r
19 DC3 51 3 83 S 115 s
20 DC4 52 4 84 T 116 t
21 NAK 53 5 85 U 117 u
22 SYN 54 6 86 V 118 v
23 ETB 55 7 87 W 119 w
24 CAN 56 8 88 X 120 x
25 EM 57 9 89 Y 121 y
26 SUB 58 : 90 Z 122 z
27 ESC 59 ; 91 [ 123 {
28 FS 60 < 92 \ '\\' 124 |
29 GS 61 = 93 ] 125 }
30 RS 62 > 94 ^ 126 ~
31 US 63 ? 95 _ 127 DEL
|