Last edited on 1998-07-04 11:34:37 by stolfi
For these plots, I first reduced the text by identifying certain groups of similar-looking characters, as follows:
"ee" --> "ch"
{ "p" "f" "k" } --> "t"
{ "ei" "a" "y" } --> "o"
{ "ii" "iii" "iiii" } --> "i"
{ "j" "g" "m" } --> "d"
So, for example, "qopsheedy ytcheedy daiin otam" would become
"qotshchdo otchchdo doin otod". Then I deleted all
word breaks (but not line breaks) and split the resulting
strings into the character groups, or "elements", of my
OKOKOKO paradigm ---
which, under the transformations above, gets reduced to the
following "element classes":
o
ch sh
che she
t
te
cth
cthe
ct
ith
d id
de
n in
r ir
l il
s is
q
x
The elements in boldface occur more than 15 times in the
whole text. There were about 250 failures of the OKOKOKO paradigm
(mostly extra "e"s and "i"s), or about 2.5 every 1000
elements.
The initial coordinates of each page are the relative frequencies of these element-classes in that page. To produce the plots, I picked three mutually orthogonal unit-length vectors X, Y, and Z, in 50-dimensional element-class frequency space, and projected the page points onto them.
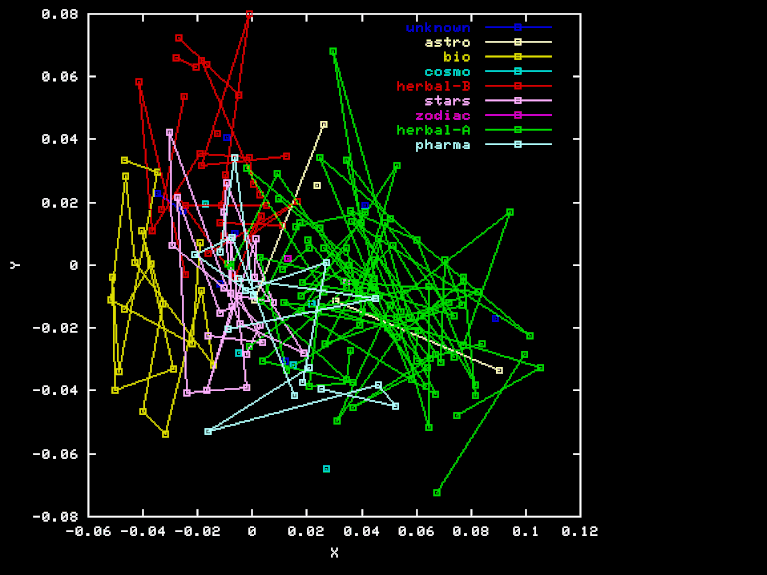
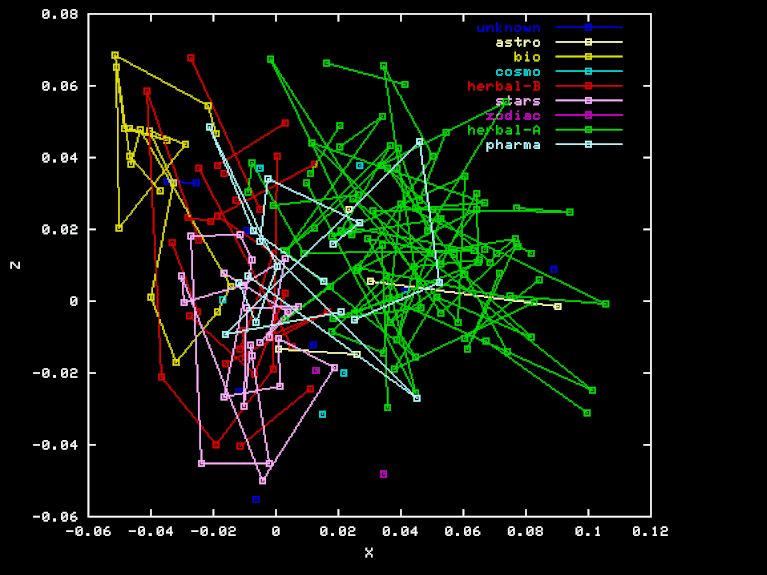
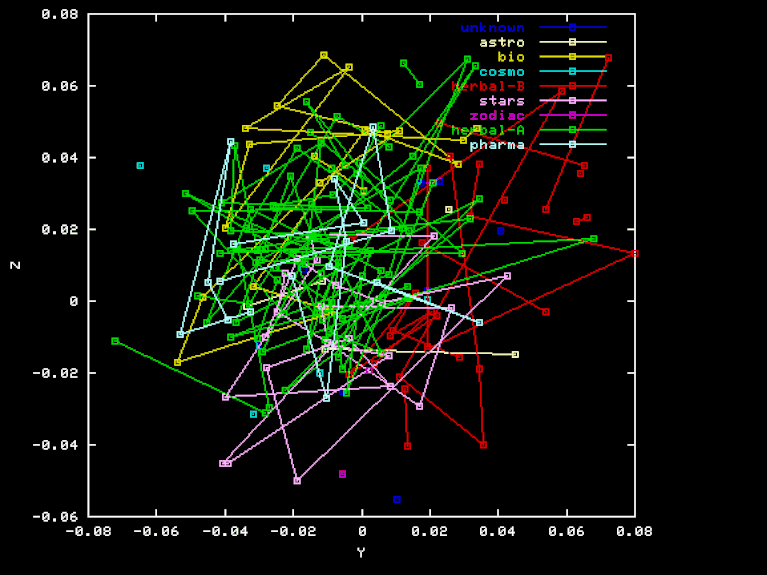
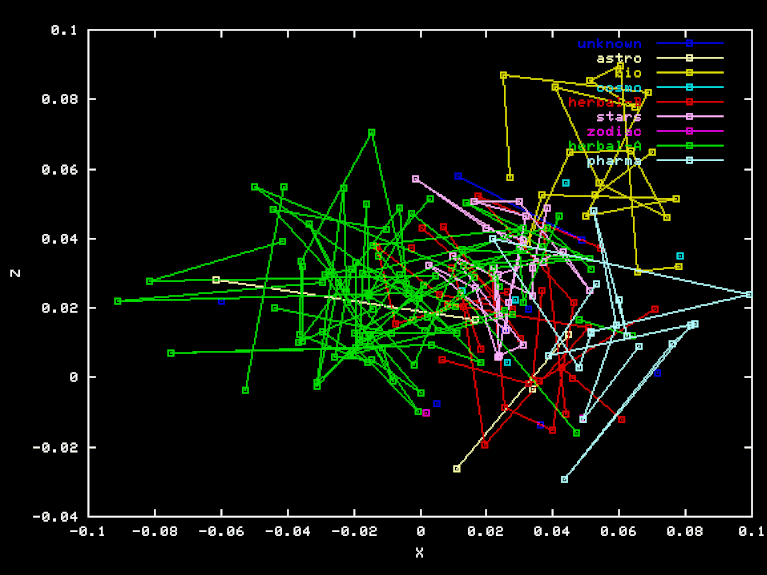
For the "Herbal" projection, the X, Y, and Z axes are the result of Gram-Schmidt orthogonalization applied to the vectors HEA-TOT, HEB-TOT BIO-TOT, where TOT is the element-class frequencies for the whole sample, and HEA, HEB and BIO are the frequencies for the Herbal-A, Herbal-B, and biological sections, respectively. Here are the X, Y, and Z coordinates of each page in this projection.
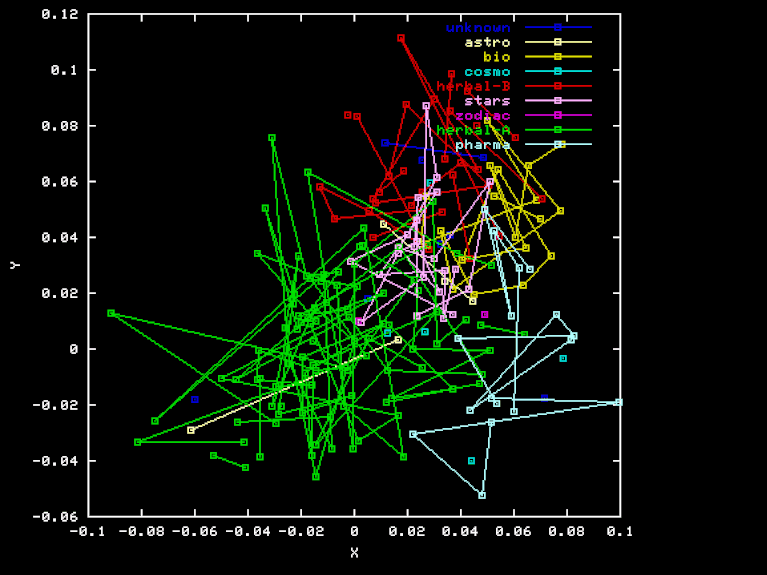
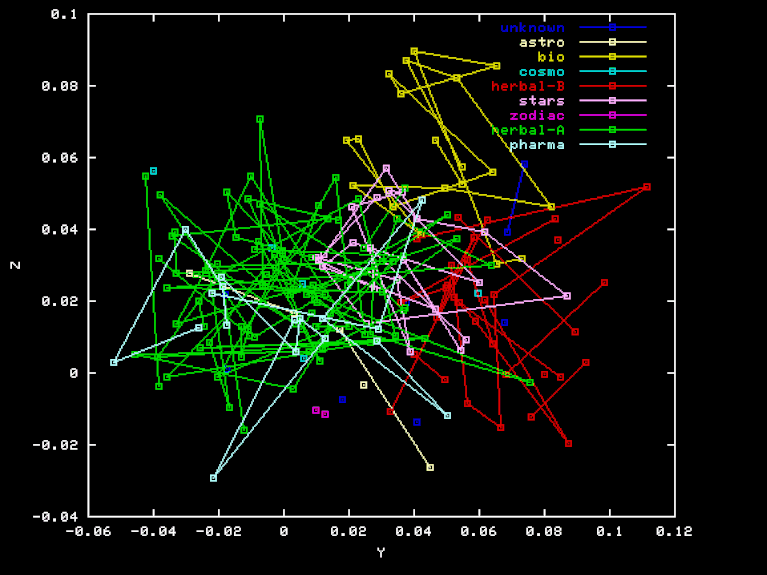
The "Pharma" projection is an attempt to discover a separation of Herbal-A pages from Pharma page, by using a different projection to three-space. The X, Y, and Z axes were obtained by orthogonalization of PHA-HEA, HEB-HEA BIO-HEA, where PHA is the vector of element-class frequencies for the "Pharma" section. Here are the X, Y, and Z coordinates of each page in this projection.
You may want to check the "raw" version of these plots, without the character identification.