Laboratório - Federated Learning com Flower
Neste laboratório vamos explorar o uso da ferramenta Flower para treinamento de modelos utilizando aprendizado federado. Será apresentado o que é o aprendizado federado, incluindo o algoritmo tradicional utilizado FedAvg e os principais desafios. Além disso, será apresentado um exemplo de implementações para códigos do cliente e servidor que permitirão o treinamento federado de modelos. Ao final desse laboratório, você será capaz de aplicar técnicas de aprendizado federado em outros problemas e desenvolver soluções eficientes para os principais desafios apresentados.
O que é Federated Learning
O Aprendizado Federado (Federated Learning) é uma abordagem de aprendizado de máquina distribuída que permite treinar modelos diretamente nos dispositivos de borda (smartphones, tablets, computadores) sem que os dados saiam desses dispositivos. Isso preserva a privacidade dos dados enquanto ainda contribui para o treinamento de modelos globais. Em resumo, o processo pode ser descrito da seguinte forma
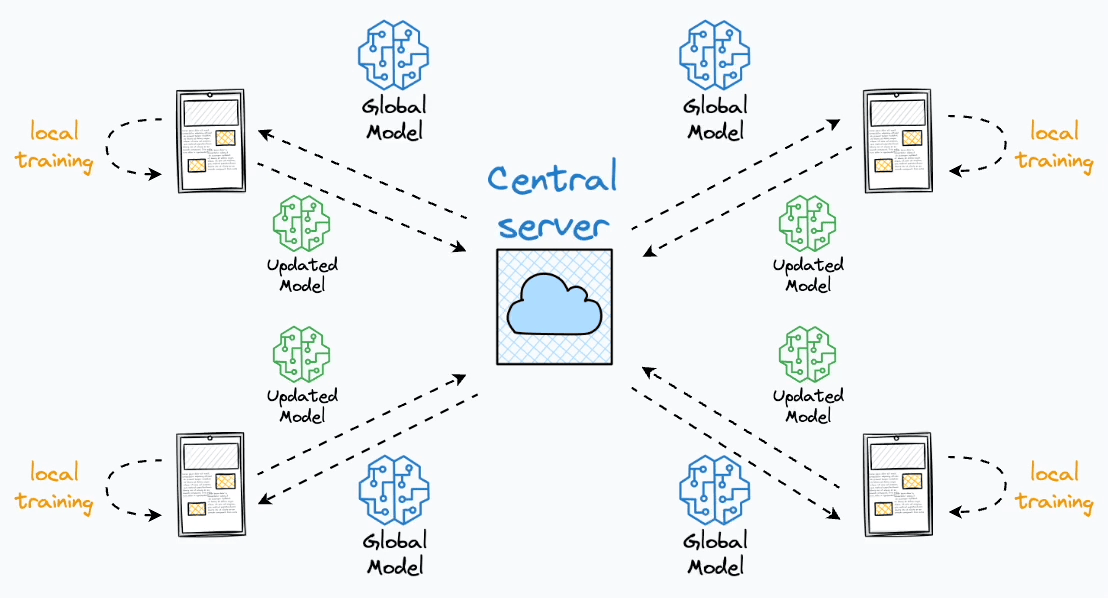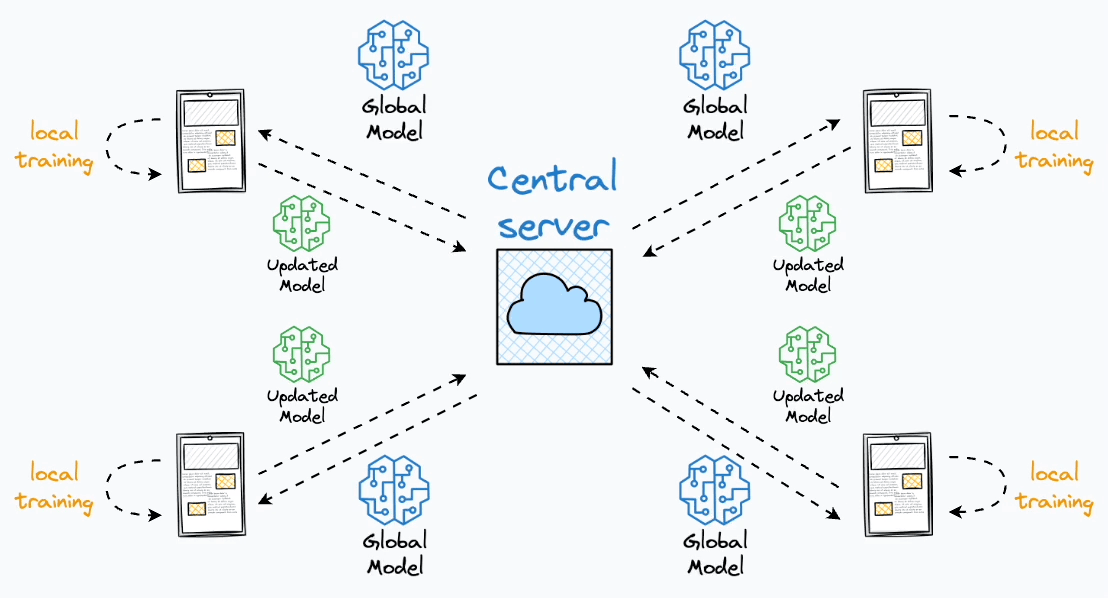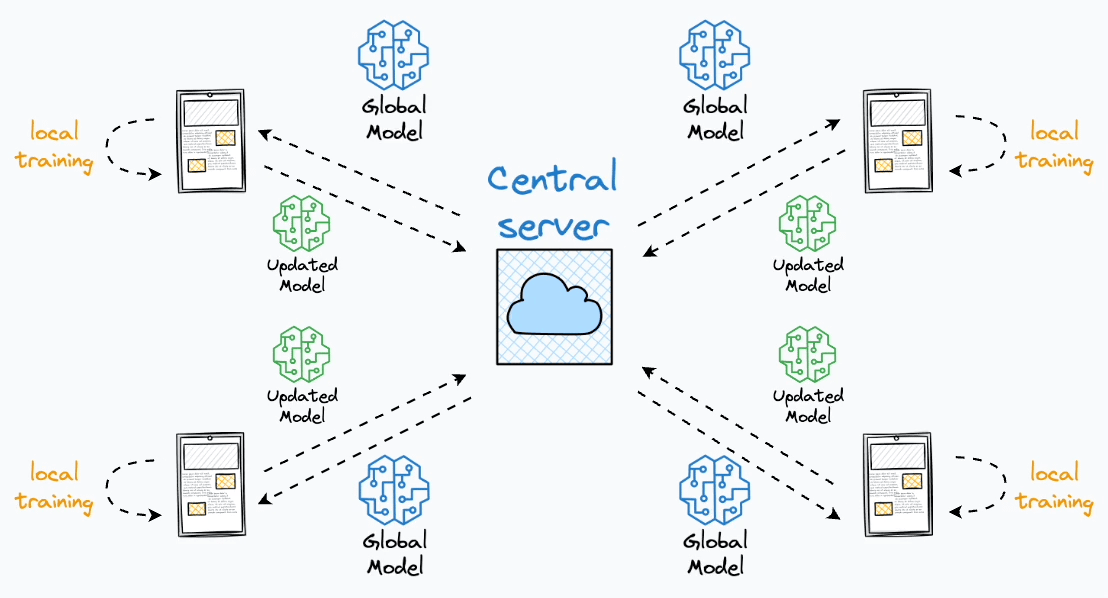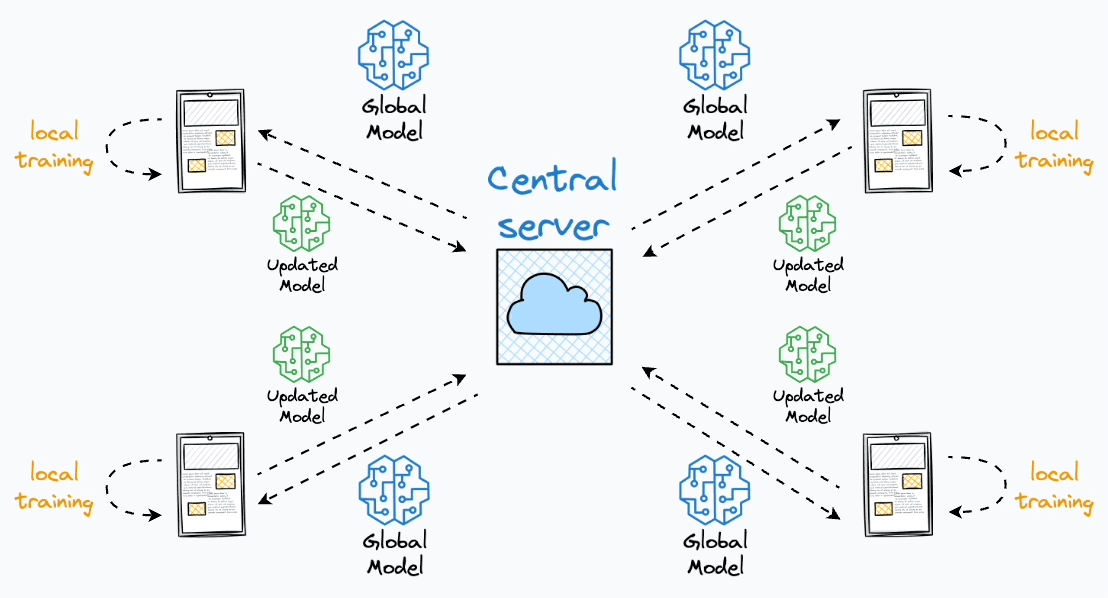
O processo de treinamento ocorre em rodadas de comunicação, cada rodada é composta pelos seguintes passos:
- Seleção de Clientes: O servidor central seleciona um subconjunto de clientes \(k \in \mathcal{S} \subseteq N\) utilizando algum algoritmo que serão responsáveis por realizar o treinamento do modelo na rodada de comunicação atual. Dessa forma, para cada cliente selecionado o servidor envia o weights \(w_t\) do modelo agregado na última rodada de comunicação.
- Treinamento Local: Os clientes selecionados recebem os pesos (\(w_t\)) do servidor e aplicam em seu modelo local. Em seguida, os clientes realizam o treinamento do modelo com seus dados locais \(D_k\) de forma privada, da seguinte forma \(w^k_t = w_t - \eta \nabla \mathcal{L}(w_t, D_k)\)0
- Compartilhamento de Modelos: Após o treinamento do modelo, cada cliente compartilha os novos pesos produzidos \(w_t^k\) com o servidor, para que seja realizado a combinação do conhecimento de cada cliente.
- Agregação de Modelos: O servidor recebe os modelos treinados e agrega os conhecimentos baseado em um algoritmo de agregação, gerando um novo modelo agregado para ser distribuído para os clientes na nova rodada de comunicação.
O Framework Flower
O Flower é um framework de código aberto projetado para facilitar o desenvolvimento de sistemas de aprendizado federado. Ele permite a construção de modelos colaborativos entre dispositivos e organizações sem a necessidade de centralizar os dados. Flower oferece uma arquitetura altamente modular e flexível, permitindo adaptar algoritmos de aprendizado federado a diferentes cenários, seja cross-device (com milhões de dispositivos) ou cross-silo (entre organizações).
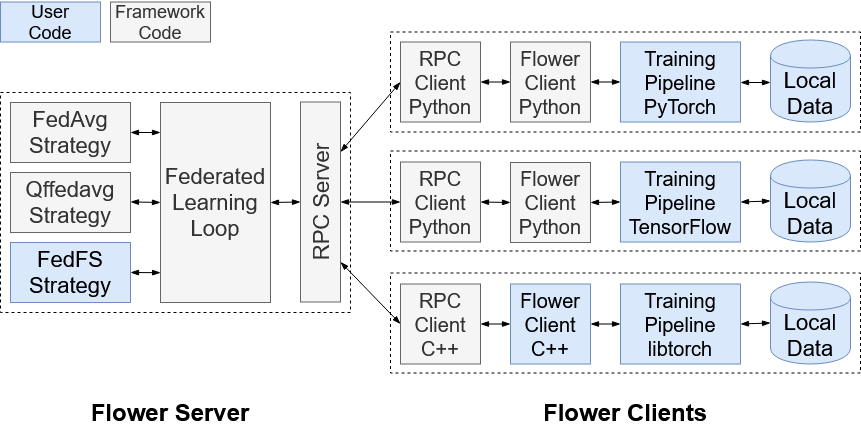
Principais características do Flower:
- Modularidade: Permite a personalização de várias partes do pipeline de aprendizado federado, como estratégias de agregação e comunicação.
- Suporte para múltiplas plataformas: É compatível com diferentes frameworks de aprendizado de máquina, como TensorFlow e PyTorch.
- Escalabilidade: Projetado para escalas grandes, suportando desde alguns dispositivos até milhões de participantes.
- Facilidade de uso: Fornece uma API simples, facilitando o desenvolvimento rápido de experimentos de aprendizado federado. Flower é amplamente utilizado em pesquisas e na indústria para explorar e implementar soluções de aprendizado federado com flexibilidade e escalabilidade.
Note
No framework já existem diversas soluções da literatura para seleção de clientes, agregação de modelos, compressão e comunicação eficientes já implementadas.
O Algoritmo - Federated Averaging (FedAvg)
O FedAvg (Federated Averaging) é um dos algoritmos mais conhecidos para Aprendizado Federado, introduzido por McMahan et al. em 2017. Ele realiza uma média ponderada das atualizações de modelo treinadas em diferentes dispositivos locais para construir um modelo global. A qual é calculada da seguinte forma: onde \(p_k = \displaystyle\frac{|D_k|}{\sum_{i \in \mathcal{S}}|D_i|}\) e \(w_{t+1}\) é o novo modelo agregado, e \(w_t^k\) é os pesos do modelo compartilhado pelo cliente \(k\). De modo geral, o FedAvg faz uma média dos pesos recebidos em relação ao tamanho do dataset de cada cliente, de modo que clientes que possuam mais dados tenham mais peso no momento da agregação.
Desafios de FL
Existem diversos desafios no aprendizado federado, incluindo: (i) dados não identicamente distribuídos e não identicamente balanceados (i.e., dados não-IID); (ii) overhead de comunicação; (iii) seleção de clientes; (iv) heterogeneidade sistêmica; (v) envenenamento de dados e modelo. Entretanto, nesse laboratório vamos focar apenas nos dados não-IID.

o problema dos dados não-IID (Independent and Identically Distributed) ocorre quando os dados distribuídos entre os dispositivos participantes não seguem a mesma distribuição estatística. Isso significa que os dados locais de cada dispositivo podem ser muito diferentes em termos de características, padrões ou classes representadas. Esse desequilíbrio afeta negativamente o desempenho do modelo global pelos seguintes motivos:
-
Diversidade de Dados: Dispositivos podem ter dados de categorias ou distribuições diferentes. Por exemplo, em um cenário de classificação de imagens, alguns dispositivos podem ter apenas imagens de gatos, enquanto outros têm apenas imagens de cachorros. Isso dificulta a generalização do modelo global.
-
Desempenho Inconsistente: O modelo pode se adaptar bem aos dados de certos dispositivos, mas falhar em dispositivos cujos dados são muito diferentes, levando a um desempenho global inconsistente.
- Convergência Mais Lenta: Treinar modelos com dados não-IID pode resultar em atualizações de modelos locais que não convergem facilmente para uma solução global eficiente.
Note
Os dados não-IID introduzem um problema conhecido como client drift, onde o treinamento de um ou mais clientes podem desviar o aprendizado do modelo do mínimo global quando realizados a agregação dos modelos.
Exemplos Dados IID vs Não-IID com Flower Datasets
O Flower Datasets é um módulo do flower que permite o particionamento de datasets de diferentes maneiras (i.e., IID e não-IID) de forma bem simples.
Tip
O flower datasets pode ser instalado via pip utilizando o comando pip install flower_datasets
Importando módulos
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import IidPartitioner, DirichletPartitioner
from flwr_datasets.visualization import plot_label_distributions, plot_comparison_label_distribution
Partionamento IID
Vamos criar um dataset federado utilizando o FederatedDataset, onde devemos informar qual dataset queremos utilizar e o particionador. Para o particionamento dados IID vamos utilizar o IidPartitioner o recebe como parâmetro a quantidade de partições que devem ser geradas, ou seja, uma partição para cada cliente. No exemplo estamo utilizando 20 partições
fds_iid = FederatedDataset(
dataset="cifar10",
partitioners={"train": IidPartitioner(num_partitions=20)})
partitioner = fds_iid.partitioners["train"]
Note
Podemos usar os datasets tradicionais presentes das bibliotecas TensorFlow e Pytorch como também podemos utilizar os datasets disponíveis no HuggingFace Datasets 🤗 apenas informando o nome do dataset que queremos utilizar.
Após a definição do dataset federado podemos gerar visualizações para entender como ficou o particionamento de cada cliente com o método plot_label_distributions do que utiliza o partcionador para gerar as visualizações.
figure, axis, dataframe = plot_label_distributions(
partitioner=partitioner,
label_name="label",
size_unit="percent",
plot_type="heatmap",
legend=True,
cmap='inferno',
figsize=(15, 5),
plot_kwargs={"annot": True},
)

Particionamento Não-IID
Para o dataset não-IID, basta alterar o particionador. Dessa forma, vamos utilizar o DirichletPartitioner o qual utiliza uma distribuição de Dirichlet para fazer o particionamento. Essa distribuição utiliza um parâmetro alpha que indica o qual não-iid será o particionamento.
fds_niid = FederatedDataset(
dataset="cifar10",
partitioners={
"train": DirichletPartitioner(
num_partitions=20,
partition_by="label",
alpha=0.1,
min_partition_size=0,
),
},
)
partitioner = fds_niid.partitioners["train"]

Explorando parâmetros alpha
Para entender como o parâmetro alpha da distribuição de Dirichlet funciona, podemos gerar diferentes partições com diferentes valores de alpha e analisar como ficou tal divisão. Dessa forma, podemos utilizar o seguinte código.
partitioner_list = []
alpha_list = [10_000.0, 100.0, 1.0, 0.1, 0.01, 0.00001]
for alpha in alpha_list:
fds = FederatedDataset(
dataset="cifar10",
partitioners={
"train": DirichletPartitioner(
num_partitions=20,
partition_by="label",
alpha=alpha,
min_partition_size=0,
),
},
)
partitioner_list.append(fds.partitioners["train"])
alpha
fig, axes, dataframe_list = plot_comparison_label_distribution(
partitioner_list=partitioner_list,
label_name="label",
cmap="inferno",
figsize=(15, 5),
titles=[f"Alpha = {alpha}" for alpha in alpha_list],
)

Tip
Como modelos ver, quanto maior o valor de alpha as partições ficam mais IID. Do mesmo modo, quanto menor o valor de alpha mais não-IID se torda o dataset
Como o Flower Funciona?
Para entender o processo de treinamento do framework Flower, é importante entender o seguinte diagrama
sequenceDiagram
autonumber
Strategy->Servidor: initialize_parameters()
Strategy-->>Servidor: Parameters
loop Treinamento
Servidor->>Strategy: configure_fit()
Strategy-->>Servidor: List[(S, Parameters)]
Note right of Servidor: FitIns são msg enviadas aos <br> clientes S selecionados com <br> Parâmetros do modelo e <br> métricas adicionais
Servidor->>Client 1: FitIns
Note right of Client 1: fit()
Servidor->>Client 2: FitIns
Note right of Client 2: fit()
Client 1-->>Servidor: FitRes
Client 2-->>Servidor: FitRes
Note right of Servidor: FitRes msg contedo <br> Parametros atualizados, <br> tamanho do dataset <br> métricas adicionais {'chave' : valor}
Servidor->>Strategy: aggregate_fit(List[FitRes])
Strategy-->>Servidor: modelo_aggregado
end
Strategy implementada, esse passo é essencial, pois todos os clientes devem iniciar com os mesmos parâmetros. Em seguida, os seguintes passos acontecem a cada rodada de comunicação:
- configure_fit(): esse método seleciona quais os clientes vão receber os parâmetros atuais do modelo para realizar o treinamento. Ele deve retornar uma Tupla
List[Tuple[ClientProxy, FitIns]], ondeClientProxyé um proxy que identifica a conexão com um cliente, eFitInsé uma mensagem que contém os parâmetros do modelo e configurações. - fit() após a definição dos clientes, o servidor vai enviar uma mensagem FitIns para cada cliente na lista que retornou do
configure_fit()ao receber essas mensagens cada cliente vai executar o bloco de código presente no métodofitimplementado no cliente. O método deve retornar, os novos parâmetros, o tamanho do dataset local e métricas adicionar no padrão{'chave': valor} - aggregate_fit() ao retornar do método
fitdo cliente o método deaggregate_fité executado no servidor, o qual recebe a lista deFitResque são as mensagens dos clientes. Nesse momento, o bloco de código implementado no aggregate_fit é executado para combinar o modelo agregado
Em seguida, o processo de avaliação se inicia, o qual é executado em toda rodada de comunicação após as iterações de treino. O processo de evaluate tem a mesma sequência entretanto, os métodos executados são: configure_evaluate() no servidor, evaluate() no cliente e aggregate_evaluate() no servidor
Implementação Cliente
Após entender o funcionamento do framework vamos implementar um treinamento federado com o MNIST para 50 clientes com particionamento IID e não-IID. Vamos iniciar a implementação com o código do cliente, o qual é uma classe que extende fl.client.NumPyClient. Nessa classe, os seguintes métodos serâo implementados:
- init: o construtor da classe para inicialização dos atributos necessários
- get_parameters: para coletar os pesos do modelo durante a inicialização
- load_data: para carregar os dados particionados de cada cliente
- create_model: para instânciar o modelo que será treinado:
- fit: para realizar o treinamento do modelo
- evaluate: para avaliar o modelo treinado
- log_client: para gerar os logs dos resultados
__init__()
class Cliente(fl.client.NumPyClient):
def __init__(self, cid, niid, num_clients, dirichlet_alpha):
self.cid = int(cid)
self.niid = niid
self.num_clients = num_clients
self.dirichlet_alpha = dirichlet_alpha
self.x_train, self.y_train, self.x_test, self.y_test = self.load_data()
self.model = self.create_model(self.x_train.shape)
get_parameters()
Esse método retorna os pesos do modelo, ele é importante pois é o primeiro método solicitado pela Strategy para ter os parâmetros iniciais para todos os clientes.
def get_parameters(self, config):
return self.model.get_weights()
load_data()
O método a seguir faz o particionamento do dataset MNIST utilizando o FederatedDataset separando as partições de treino e teste para cada cliente baseado em seu identificador cid. Além disso, baseado no atributo self.niid o método decide se vai ser feito um particionamento IID ou não-IID nos dados. Ao final, o conjutno de treino e teste é retornado para cada cliente
def load_data(self):
if self.niid:
partitioner_train = DirichletPartitioner(num_partitions=self.num_clients, partition_by="label",
alpha=self.dirichlet_alpha, min_partition_size=0,
self_balancing=False)
partitioner_test = DirichletPartitioner(num_partitions=self.num_clients, partition_by="label",
alpha=self.dirichlet_alpha, min_partition_size=0,
self_balancing=False)
else:
partitioner_train = IidPartitioner(num_partitions=self.num_clients)
partitioner_test = IidPartitioner(num_partitions=self.num_clients)
fds = FederatedDataset(dataset='mnist', partitioners={"train": partitioner_train})
train = fds.load_partition(self.cid).with_format("numpy")
fds_eval = FederatedDataset(dataset='mnist', partitioners={"test": partitioner_test})
test = fds_eval.load_partition(self.cid).with_format("numpy")
return train['image']/255.0, train['label'], test['image']/255.0, test['label']
create_model()
Esse método cria o modelo que será utilizado no treinamento federado, é um modelo simples para o MNIST que recebe como parâmetro o formato dos dados de entrada para criação da primeira camada do modelo.
def create_model(self, input_shape):
model = tf.keras.models.Sequential([
tf.keras.layers.Input(shape=(28, 28, 1)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax'),
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
Note
É importante destacar que esse é apenas um modelo de exemplo, outros modelos podem ser implementados nesse método
fit()
O método recebe como parâmetros os pesos do modelo, encaminhado pelo servidor e as configurações adicionais que são passadas no forma {'chave' : valor}. No exemplo, apenas é informado pesos do modelo e a rodada atual do treinamento. Assim, o cliente recebe os parameters que são os pesos do modelo agregado, aplica em seu modelo local com self.model.set_weights(parameters) realiza o treinamento do modelo com seus dados locais utilizando o método self.model.fit(), atualiza os parâmetros após o treinamento trained_parameters, cria uma mensagem de resposta com dados adicionais, incluindo: identificador, acurácia e loss e retorna para o servidor.
def fit(self, parameters, config):
self.model.set_weights(parameters)
history = self.model.fit(self.x_train, self.y_train, epochs=1)
acc = np.mean(history.history['accuracy'])
loss = np.mean(history.history['loss'])
trained_parameters = self.model.get_weights()
fit_msg = {
'cid' : self.cid,
'accuracy': acc,
'loss' : loss,
}
self.log_client('train.csv', config['server_round'], acc, loss)
return trained_parameters, len(self.x_train), fit_msg
evaluate()
O método recebe os parâmetros agregados e altera os pesos do modelo do cliente com o método self.model.set_weights(parameters) em seguida realiza a avaliação do modelo com os dados de teste self.model.evaluate(self.x_test, self.y_test). Ao final, o método cria uma mensagem com métricas adicionais que será encaminhada para o servidor
def evaluate(self, parameters, config):
self.model.set_weights(parameters)
loss, acc = self.model.evaluate(self.x_test, self.y_test)
eval_msg = {
'cid' : self.cid,
'accuracy': acc,
'loss' : loss
}
self.log_client('evaluate.csv', config['server_round'], acc, loss)
return loss, len(self.x_test), eval_msg
log_cliente()
Método utilizado para geração de logs. Recebe como parâmetro o filename e as métricas que serão utilizadas para o log.
def log_client(self, file_name, server_round, acc, loss):
with open(file_name, 'a') as file:
file.write(f'{server_round}, {self.cid}, {acc}, {loss}\n')
Note
Esse é apenas um exemplo de como podemos guardar os logs para gerar as visualizações. Outros métricas podem ser monitoradas de acordo com a necessidade do problema.
Implementação Servidor
Agora vamos fazer a implementação do código do servidor. Em nossa implementação, o servidor é representado por uma classe que extende fl.server.strategy.FedAvg onde vamos desenvolver os seguintes métodos:
- init o construtor da classe para inicialização dos atributos necessários
- configure_fit: para realizar a seleção dos clientes para o treinamento
- aggregate_fit: para agregar os modelos recebidos dos clientes selecionados durante o treinamento
- configure_evaluate: para selecionar os clientes que vão realizar a as avaliações do modelo com seus dados locais
- aggregate_evaluate: para agregar as avaliações dos clientes
__init__()
O método inicializa apenas atributos de controle a os atributos de fraction_fit e min_available_clients do FedAvg. O primeiro informa quanto clientes serão selecionados por rodada para fazer o treinamento (i.e., em porcentagem) e o segundo informa a quantidade mínima de clientes necessárias para iniciar o processo federado.
class Servidor(fl.server.strategy.FedAvg):
def __init__(self, num_clients, dirichlet_alpha, fraction_fit=0.2):
self.num_clients = num_clients
self.dirichlet_alpha = dirichlet_alpha
super().__init__(fraction_fit=fraction_fit min_available_clients=num_clients)
configure_fit()
O método configure_fit prepara a tupla de lista clientes, parâmetros e configurações. Dessa forma, os parâmetros são enviados para a lista de clientes selecionados com suas respectivas configurações. Como configurações, o servidor está enviando a rodada atual para os clientes
def configure_fit(self, server_round, parameters, client_manager):
"""Configure the next round of training."""
config = {
'server_round': server_round,
}
fit_ins = FitIns(parameters, config)
sample_size, min_num_clients = self.num_fit_clients(
client_manager.num_available()
)
clients = client_manager.sample(
num_clients=sample_size, min_num_clients=min_num_clients
)
# Return client/config pairs
print(clients)
return [(client, fit_ins) for client in clients]
Note
Note que o método client_manager.sample() está fazendo a amostragem de clientes aleatória baseado na porcentagem informada no parâmetro fraction_fit
agregate_fit()
Agora vamos agregar as atualizações informadas pelos clientes FitRes para formar o modelo agregado da rodada atual. O método aggregate_fit implementado faz a agregação utilizando o método do FedAvg. Para isso, precisamos preparar uma lista de Tuplas contendo (Parametros, numero_exemplos) para ser passado para o método aggregate() que fará a agregação. Entretanto, antes disso devemos converter os parâmetros compartilhados para ndarray para que seja possível realiazar as operações. Assim, utilizamos o método parameters_to_ndarrays(fit_res.parameters)
def aggregate_fit(self, server_round, results, failures):
parameters_list = []
for _, fit_res in results:
parameters = parameters_to_ndarrays(fit_res.parameters)
exemplos = int(fit_res.num_examples)
parameters_list.append([parameters, exemplos])
agg_parameters = aggregate(parameters_list)
agg_parameters = ndarrays_to_parameters(agg_parameters)
return agg_parameters, {}
Note
É importante destacar que ao final o modelo agregado agg_parameters deve ser transformado novamente em parâmetros para que seja possível a utilização no modelos dos clientes. Assim, utilizamos o método ndarrays_to_parameters(agg_parameters)
configure_evaluate()
Após realizar uma rodada de treinamento, o flower permite a execução de uma rodada de avaliação. Portanto, devemos realizar a processo de seleção de clientes que vão avaliar o modelo e também agregar o as avaliações. Para selecionado os clientes, implementamos o método configure_evaluate, ele é desenvolvido da mesma forma que o método de configure_fit, entretanto no exemplo a seguir, selecionamos todos os clientes para realizar a avaliação, para analisar o quão genérico o modelo treinado está.
def configure_evaluate(self, server_round, parameters, client_manager):
config = {
'server_round': server_round,
}
evaluate_ins = EvaluateIns(parameters, config)
sample_size, min_num_clients = self.num_evaluation_clients(
client_manager.num_available()
)
clients = client_manager.sample(
num_clients=sample_size, min_num_clients=min_num_clients
)
return [(client, evaluate_ins) for client in clients]
Tip
Outras estratégias de seleção de avaliação podem ser implementadas aqui, por exemplo. Caso sejá necessário utilizar uma abordagem cross-device dispositivos diferentes dos utilizados no treinamento podem ser selecionados aqui.
aggregate_evaluate()
Por fim, ao receber a avaliação dos clientes o modelo agrega e gera uma métrica de acurácia média para representar o desempenho do modelo. A acurácia média, é calculada baseada nas acurácias informadas por cada cliente.
def aggregate_evaluate(self, server_round, results, failures):
accuracies = []
for _, response in results:
acc = response.metrics['accuracy']
accuracies.append(acc)
avg_acc = sum(accuracies)/len(accuracies)
print(f"Rodada {server_round} acurácia agregada: {avg_acc}")
return avg_acc, {}
Executando Treinamento Federado
Com a definição dos códigos do cliente e servidor, podemos iniciar o treinamento do modelo de forma federada. Podemos realizar esse processo de várias forma, por exemplo utilizando containers em um ambiente Docker, iniciar cada cliente em terminais ou em máquinas diferentes. Porém, nesse exemplo vamos utilizar o próprio simulado do flower que gerencia o treinamento federado utilizando ray.
Flower Simulation
Primeiramente devemos instalar o simulado utilizando o seguinte comando:
pip install -U "flwr[simulation]"
Warning
É importante executar todas as células novamente após a instalação, pois pode ocorrer do python não idenficiar a instalação do fl.simulation, uma vez que o módulo fl já tinha sido instanciado.
Após a instalação, podemo iniciar a simulação. No exemplo, estão sendo definidas algumas variáveis para controle da simulação, incluindo: (i) quantidade de clientes; (ii) formato das partições IID ou não-IID; (iii) o alpha para as partições não-IID; e (iv) a porcentagem de clientes que serão selecionados para o durante cada rodada de treinamento.
NCLIENTS = 10
NROUNDS = 20
NIID = True
DIRICHLET_ALPHA = 0.1
FRACTION_FIT = 0.2
cid : str que é passado para cada cliente informando seu identificador. Esse cid será a base para controle das partições e treinamento dos clientes. Dessa forma, a função deve instaciar o cliente de acordo com nossa implementação passando os parâmetros para o construtor, no nosso caso Cliente(cid, NIID, NCLIENTS, DIRICHLET_ALPHA). Por fim, o retorno dessa função deve ser feito utilizando o client.to_client()
def create_client(cid):
client = Cliente(cid, NIID, NCLIENTS, DIRICHLET_ALPHA)
return client.to_client()
Servidor(num_clients=NCLIENTS, dirichlet_alpha=DIRICHLET_ALPHA, fraction_fit=FRACTION_FIT). Em seguida, implementamos um método run_simulation() que é responsável por iniciar a simulação. O método faz uma call para fl.simulation.start_simulation(), passando a função para criar os clientes, a quantidade de clientes desejada, a configuração do servidor (i.e., nesse caso a quantidade de rodadas de comunicação), e por fim, a stratégia que será utilizada para agregação e gerenciamento dos clientes (i.e., nossa classe servidor instanciada em self.server)
class Simulation():
def __init__(self):
self.server = Servidor(num_clients=NCLIENTS, dirichlet_alpha=DIRICHLET_ALPHA, fraction_fit=FRACTION_FIT)
def run_simulation(self):
fl.simulation.start_simulation(
client_fn = create_client,
num_clients = NCLIENTS,
config = fl.server.ServerConfig(num_rounds=NROUNDS),
strategy = self.server)
Simulation().run_simulation()
Note
Como o flower simulation é baseado em ray, podemos utilizar um dicionário para passagem de parâmetros exclusico para o ray_args, esses parâmetros incluem a quantidade de cpus e gpus desejada, o ip de um cluster head caso for executar o código em um cluster ray, porta da dashborad entre outros.
Gerando Visualizações
Com os logs gerados, podemos criar visualizações para entender o desempenho do modelo treinado. Para demostração, vamos gerar gráficos para loss e acurácia média de treino e avaliação.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df_train = pd.read_csv('train.csv', names=['server_round', 'cid', 'acc', 'loss'])
df_test = pd.read_csv('evaluate.csv', names=['server_round', 'cid', 'acc', 'loss'])
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
sns.lineplot(data=df_train, x='server_round', y='loss', ax=ax[0], color='b', label='Loss Treino')
sns.lineplot(data=df_train, x='server_round', y='acc', ax=ax[1], color='b', label='Acc Treino')
sns.lineplot(data=df_test, x='server_round', y='loss', ax=ax[0], color='r', label='Loss Teste')
sns.lineplot(data=df_test, x='server_round', y='acc', ax=ax[1], color='r', label='Acc Teste')
ax[0].set_title('Loss')
ax[1].set_title('Accuracy')
ax[0].grid(True, linestyle=':')
ax[1].grid(True, linestyle=':')
Resultados IID - Loss e Acurácia

Resultados Não-IID - Loss e Acurácia

Visualizações por Cliente
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
sns.histplot(x=df_test['acc'].values[-10:], kde=True, color='r', bins=10, ax=ax[0])
sns.barplot(x=df_test['cid'].values[-10:], y=df_test['acc'].values[-10:], color='b', ec='k', ax=ax[1])
ax[0].set_title('Distribuição de Acurácia dos Clientes')
ax[0].set_ylabel('Quantidade de Clientes')
ax[0].set_xlabel('Acurácia Teste(%)')
ax[1].set_title('Acurácia por Cliente')
ax[1].set_ylabel('Acurácia Teste')
ax[1].set_xlabel('Client ID (#)')
for _ in range(2):
ax[_].grid(True, linestyle=':')
ax[_].set_axisbelow(True)
Resultados Distribuição e Acurácia por Cliente - IID

Resultados Distribuição e Acurácia por Cliente - Não-IID

Execício - (Entregável)
Existem duas abordagens principais de aprendizado federado, sendo elas o aprendizado federado cross-silo e o cross-device, onde as principais diferenças entre eles são definidas da seguinte forma:
-
Aprendizado federado cross-device: Envolve a participação de uma grande quantidade de dispositivos de usuários finais (como smartphones, tablets, etc.). Cada dispositivo treina o modelo localmente e envia apenas atualizações do modelo (e não os dados) para um servidor central, que combina essas atualizações para criar um modelo global. Essa abordagem é adequada para cenários onde os dispositivos têm conexões intermitentes e os dados são distribuídos de forma ampla entre muitos dispositivos.
-
Aprendizado federado cross-silo: Envolve a colaboração entre entidades organizacionais (como hospitais, bancos ou diferentes empresas) que possuem grandes conjuntos de dados. Cada entidade treina o modelo com seus próprios dados, e o modelo global é formado pela agregação de modelos locais sem compartilhar os dados sensíveis. O foco é em poucas instituições que têm maior poder computacional e mais controle sobre a infraestrutura, em comparação com o cross-device.
A principal diferença está na forma como os dados são utilizados para treinamento e validação. No cross-device o treinamento é feito com um conjunto de cliente e a validação com outro conjunto de clientes (que nunca são selecionados no treinamento), ou seja, um conjuto de clientes apenas treinam e outro conjunto apenas avaliam. Por outro lado, o cross-silo os clientes possuem partições de treino e de teste também para fazer a validação. A imagem a seguir apresenta de forma visual essa descrição:

Nesse atividade, vamos implementar uma abordagem cross-device para o treinamento federado com Flower. Nesse contexto, você deve alterar o código apresentado nesse laboratório para separar os dados no formado cross-device e implementar os algoritmos de seleção para selecionar um conjunto de clientes e selecionar outro conjunto para avaliação. Além disso, será necessário gerar visualizações considerando dados IID e dados Não-IID
Tip
Para fazer a implementação cross-device será necessário alterar o método configure_fit() e também o método configure_evaluate() para fazer a seleção de diferentes conjutos dos clientes.