Laboratório 5 - Classificação de Imagens com TensorFlow & Keras
Importando os Pacotes Necessários
Começamos importando os pacotes necessários para desenvolver nossa modelo para classificação de imagens
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
Importando os Dados MNIST
O conjunto de dados MNIST é um conjunto de imagens de dígitos escritos à mão, amplamente utilizado para testar algoritmos de aprendizado de máquina. Vamos importar o conjunto de dados MNIST do TensorFlow.
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
linhas = 2
colunas = 8
fig, axs = plt.subplots(linhas, colunas, figsize=(16, 4))
axs = axs.flatten()
for i in range(linhas * colunas):
axs[i].imshow(x_train[i], cmap='gray_r')
axs[i].set_title(str(y_train[i]))
axs[i].axis('off')
plt.show()

O conjunto de dados MNIST é composto por imagens de 28x28 pixels e cada imagem representa um dígito de 0 a 9. As imagens são divididas em um conjunto de treinamento e um conjunto de teste.
Pré-processando os Dados
Antes de alimentar os dados para o modelo, é necessário pré-processá-los. Vamos normalizar as imagens dividindo cada pixel pelo valor máximo de pixel (255).
x_train, x_test = x_train / 255.0, x_test / 255.0
Definindo o Modelo
Agora que os dados estão prontos, vamos definir o modelo. Para este tutorial, vamos usar uma rede neural simples com duas camadas ocultas e uma camada de saída.
modelo_1 = tf.keras.models.Sequential()
modelo_1.add(tf.keras.layers.Flatten(input_shape=(28, 28, 1)))
modelo_1.add(tf.keras.layers.Dense(10, activation='softmax'))
A primeira camada é uma camada de achatamento (flatten), que transforma a imagem em um vetor unidimensional. As duas camadas ocultas têm 128 e 64 neurônios, respectivamente, e usam a função de ativação ReLU.

Cada neurônio em uma rede neural faz uma soma ponderada de todas as suas entradas, adiciona uma constante chamada bias e então alimenta o resultado por meio de alguma função de ativação não linear. Os pesos e biases são parâmetros que serão determinados por meio do treinamento. Eles são inicializados com valores aleatórios no início.
A imagem acima representa uma rede neural de 1 camada com 10 neurônios de saída, pois queremos classificar dígitos em 10 classes (0 a 9).
Veja como uma camada de rede neural, processando uma coleção de imagens, pode ser representada por uma multiplicação de matrizes:
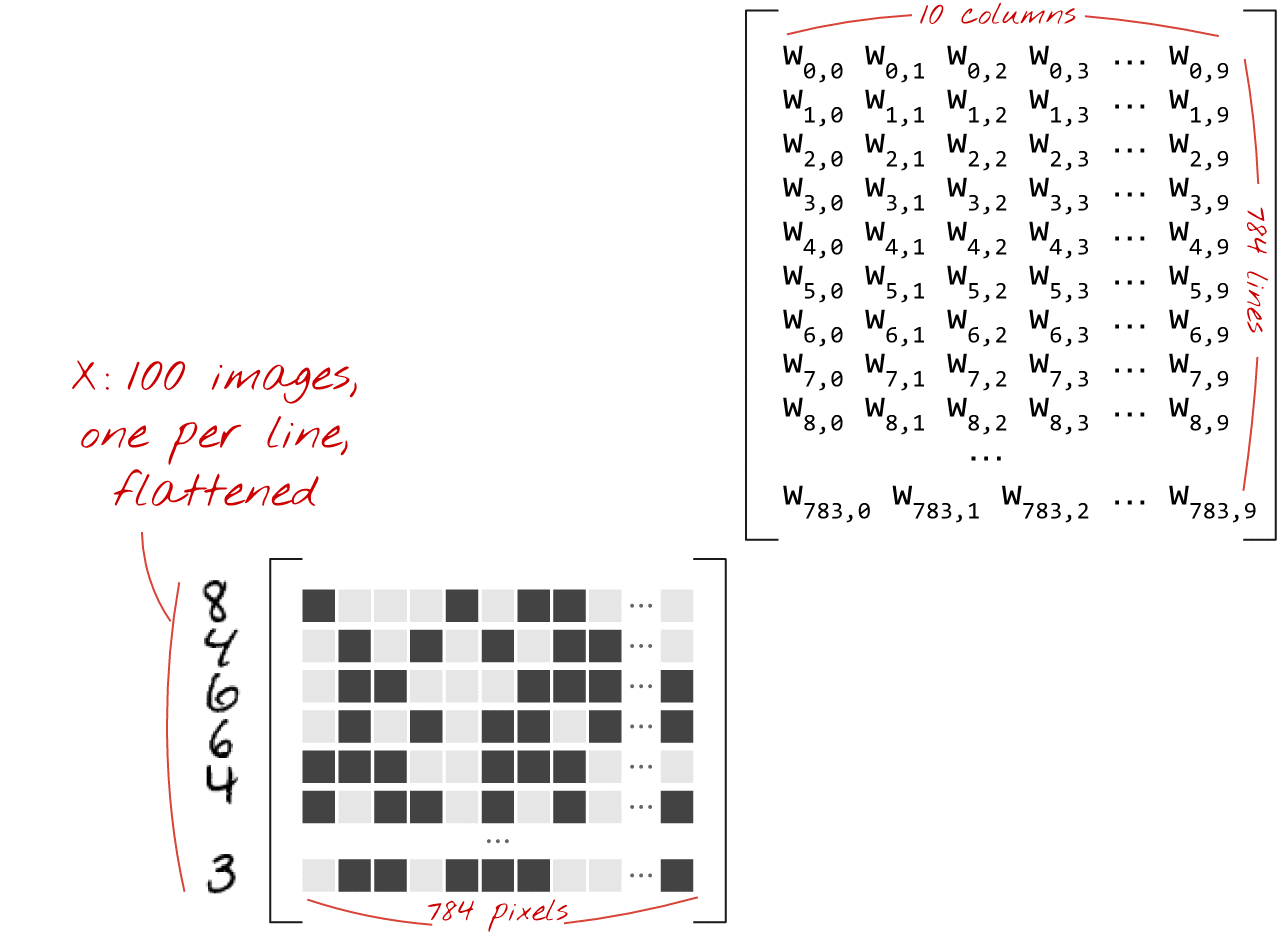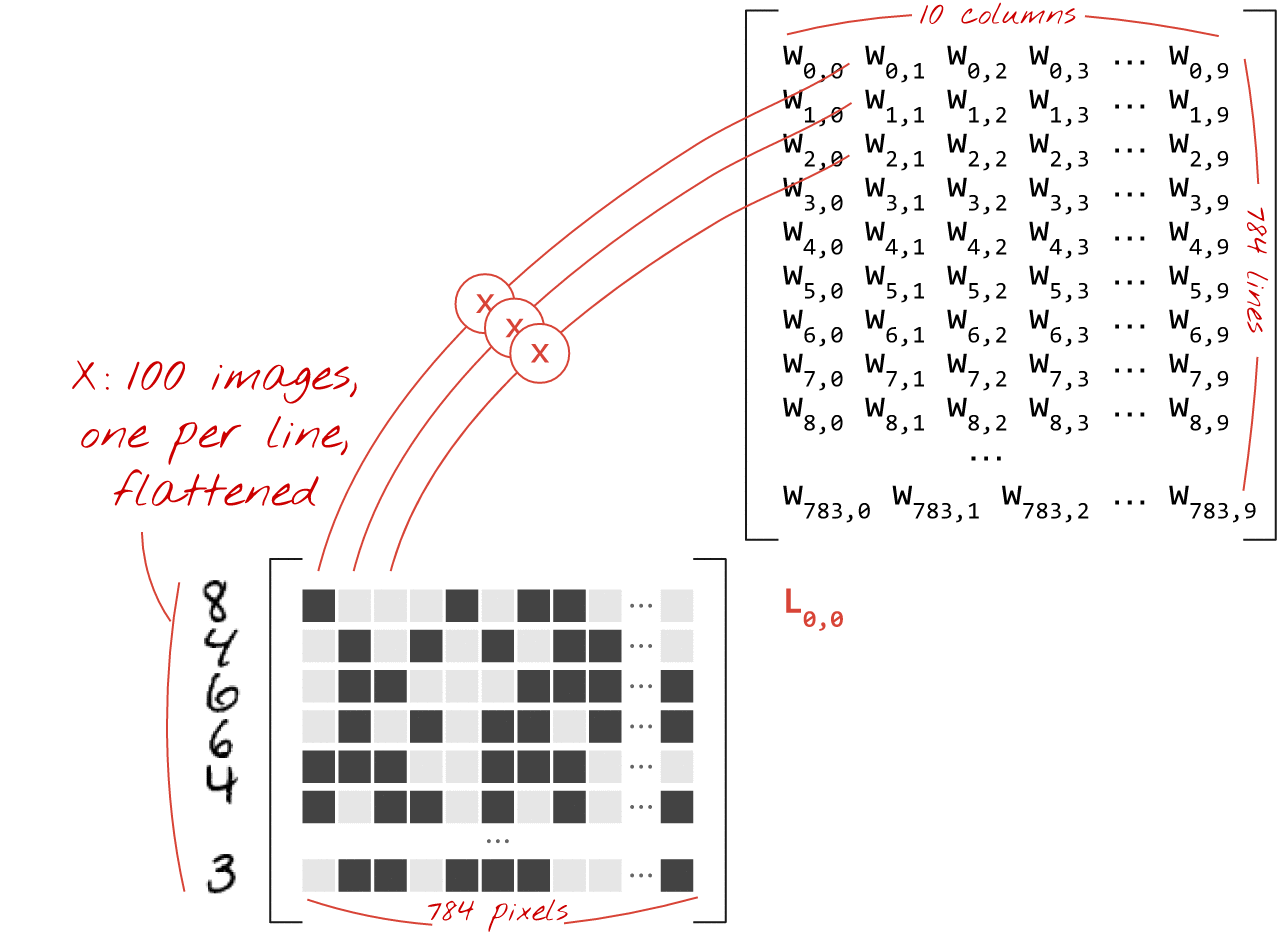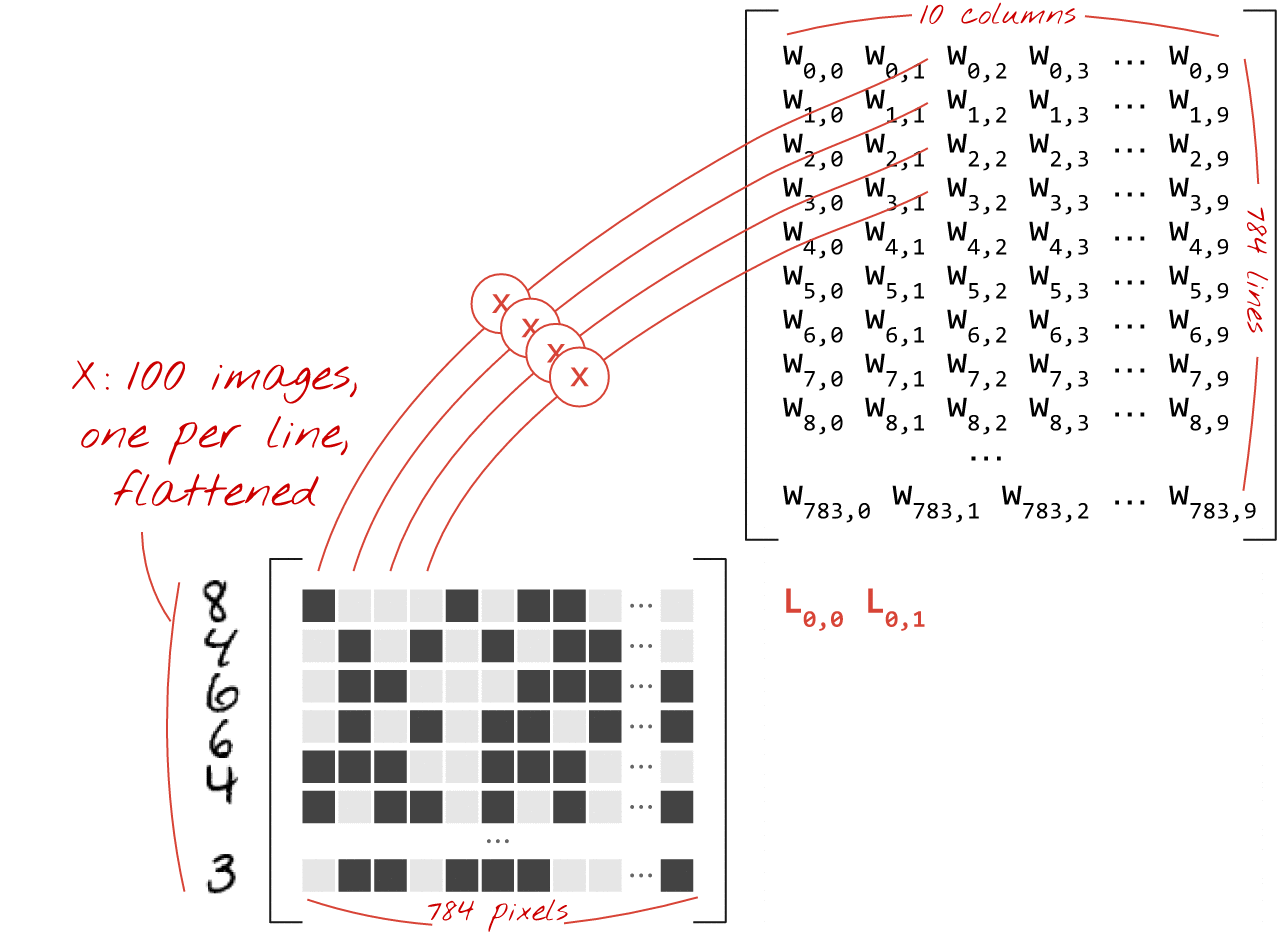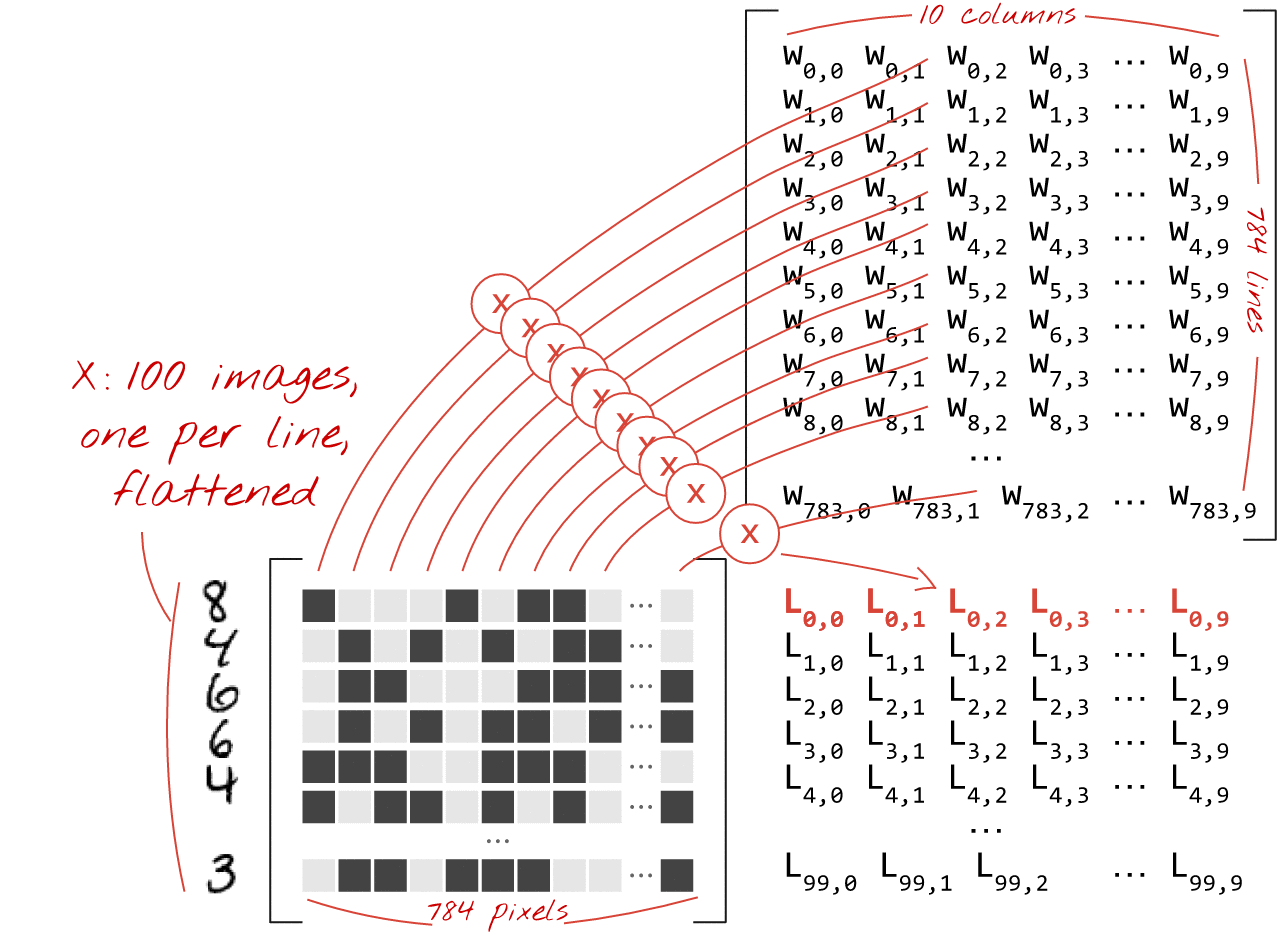
Usando a primeira coluna de pesos na matriz de pesos W, calculamos a soma ponderada de todos os pixels da primeira imagem. Essa soma corresponde ao primeiro neurônio. Usando a segunda coluna de pesos, fazemos o mesmo para o segundo neurônio e assim por diante até o 10º neurônio. Podemos então repetir a operação para as 99 imagens restantes. Se chamarmos X de matriz contendo nossas 100 imagens, todas as somas ponderadas para nossos 10 neurônios, computadas em 100 imagens, são simplesmente X.W, uma multiplicação de matriz.
Note
Cada neurônio deve agora adicionar seu bias (uma constante). Como temos 10 neurônios, temos 10 constantes de bias. Chamaremos esse vetor de 10 valores de b. Ele deve ser adicionado a cada linha da matriz previamente computada. Usando um pouco de mágica chamada "broadcasting", escreveremos isso com um simples sinal de mais.
Finalmente aplicamos uma função de ativação, por exemplo "softmax" (explicada abaixo) e obtemos a fórmula que descreve uma rede neural de 1 camada, aplicada a 100 imagens:
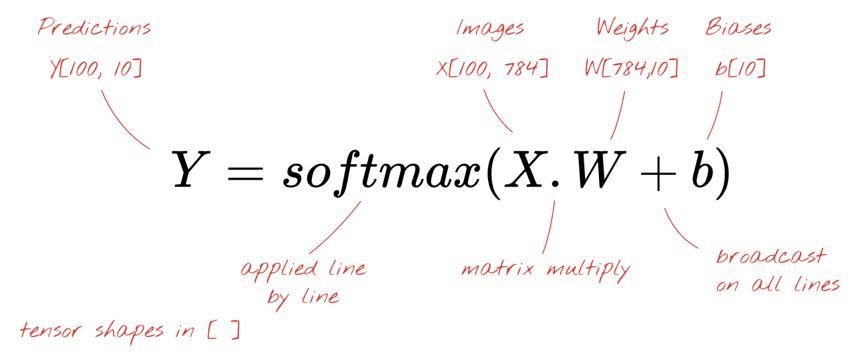
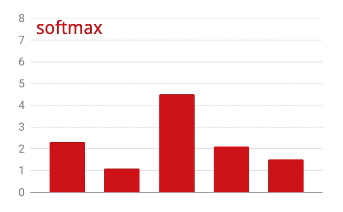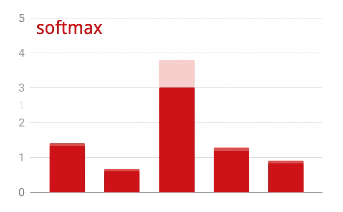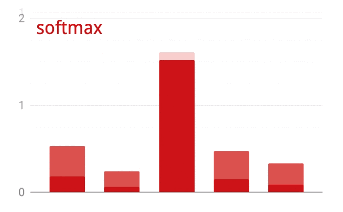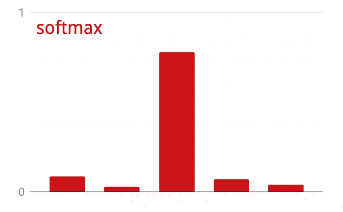
Compilando o Modelo
Antes de treinar o modelo, precisamos compilá-lo. Vamos especificar a função de perda (sparse_categorical_crossentropy), o otimizador (adam) e as métricas (accuracy).
modelo_1.compile(optimizer='sgd',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Treinando o Modelo
Agora que o modelo está compilado, vamos treiná-lo no conjunto de treinamento.
history_m1 = modelo_1.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test),
batch_size=64)
Durante o treinamento, o modelo é ajustado para minimizar a função de perda e melhorar a acurácia. O argumento epochs especifica o número de épocas (iterações) de treinamento.
Visualizando os Resultados
Podemos visualizar os resultados do treinamento usando o histórico de treinamento (history).
def plot_resultados_modelo(history):
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ax = ax.flatten()
ax[0].plot(history.history['accuracy'], label='Acurácia Treinamento', marker='o', color='blue')
ax[0].plot(history.history['val_accuracy'], label='Acurácia Validação', marker='o', color='red', linestyle='--')
ax[1].plot(history.history['loss'], label='Loss Treinamento', marker='o', color='blue')
ax[1].plot(history.history['val_loss'], label='Loss Validação', marker='o', color='red', linestyle='--')
for _ in range(2):
ax[_].set_xlabel('Época')
ax[_].set_ylabel('Acurácia' if _ == 0 else 'Loss')
ax[_].legend()
ax[_].grid(True, linestyle=':')
plot_resultados_modelo(history_m1)

Adicionando Mais Camadas
Para melhorar a precisão do reconhecimento, adicionaremos mais camadas à rede neural.
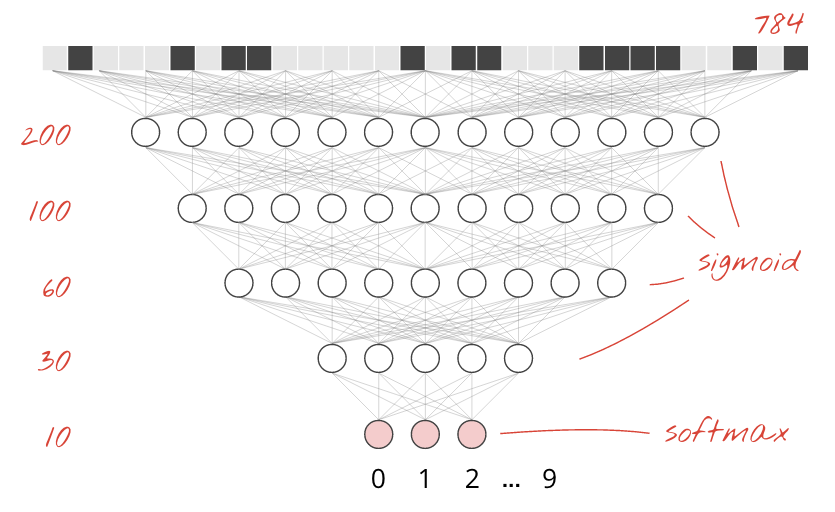
Mantemos softmax como a função de ativação na última camada porque é o que funciona melhor para a classificação. Nas camadas intermediárias, porém, usaremos a função de ativação mais clássica:
modelo_2 = tf.keras.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28, 1,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
modelo_2.compile(optimizer='sgd',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history_m2 = modelo_2.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test), batch_size=64,
verbose=2)
plot_resultados_modelo(history_m2)

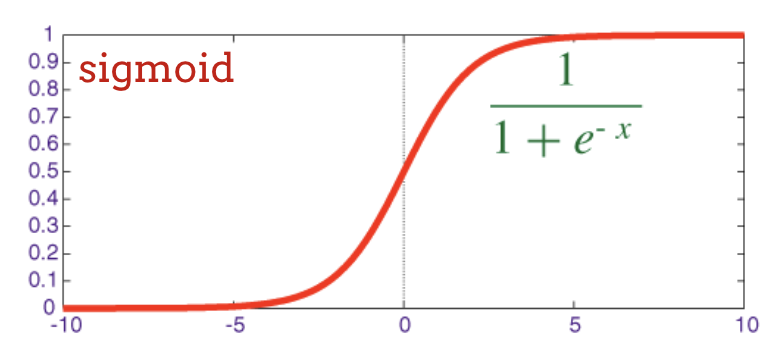
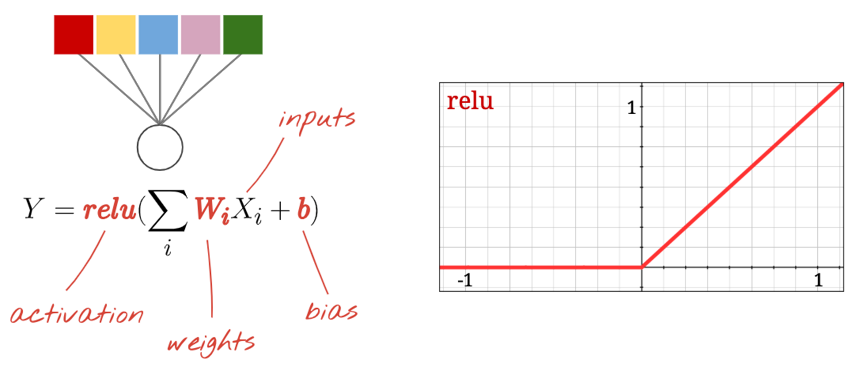
Ativação ReLu
A função de ativação sigmoide é bastante problemática em redes profundas. Ele esmaga todos os valores entre 0 e 1 e, quando você faz isso repetidamente, as saídas dos neurônios e seus gradientes podem desaparecer completamente. Foi mencionado por razões históricas, mas as redes modernas usam a RELU (Unidade Linear Retificada) que se parece com isso:
modelo_3 = tf.keras.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28, 1,)),
tf.keras.layers.Dense(200, activation='relu'),
tf.keras.layers.Dense(60, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
modelo_3.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history_m3 = modelo_3.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test),
batch_size=64, verbose=2)
plot_resultados_modelo(history_m3)

Utilizando CNNs
As redes neurais convolucionais aplicam uma série de filtros que podem ser aprendidos à imagem de entrada. Uma camada convolucional é definida pelo tamanho do filtro (ou kernel), o número de filtros aplicados e o passo. A entrada e a saída de uma camada convolucional têm, cada uma, três dimensões (largura, altura, número de canais), começando com a imagem de entrada (largura, altura, canais RGB). Ao empilhar camadas convolucionais, a largura e a altura da saída podem ser ajustadas usando um passo > 1 ou com uma operação de agrupamento máximo. A profundidade da saída (número de canais) é ajustada usando mais ou menos filtros.
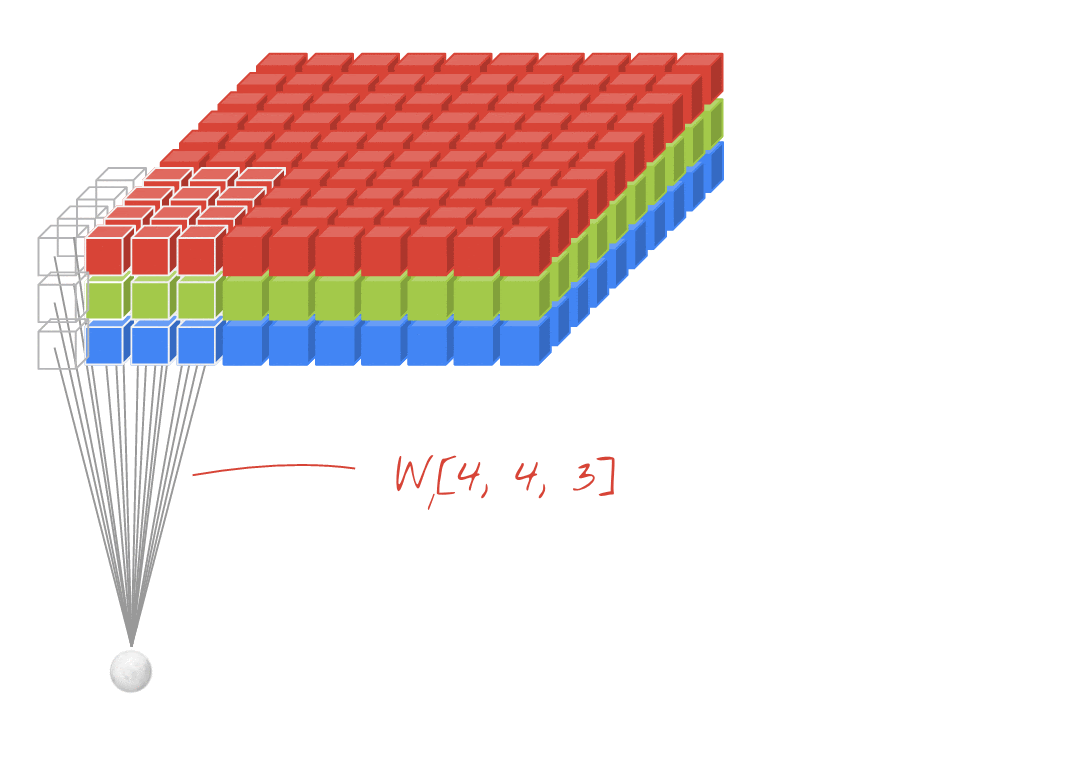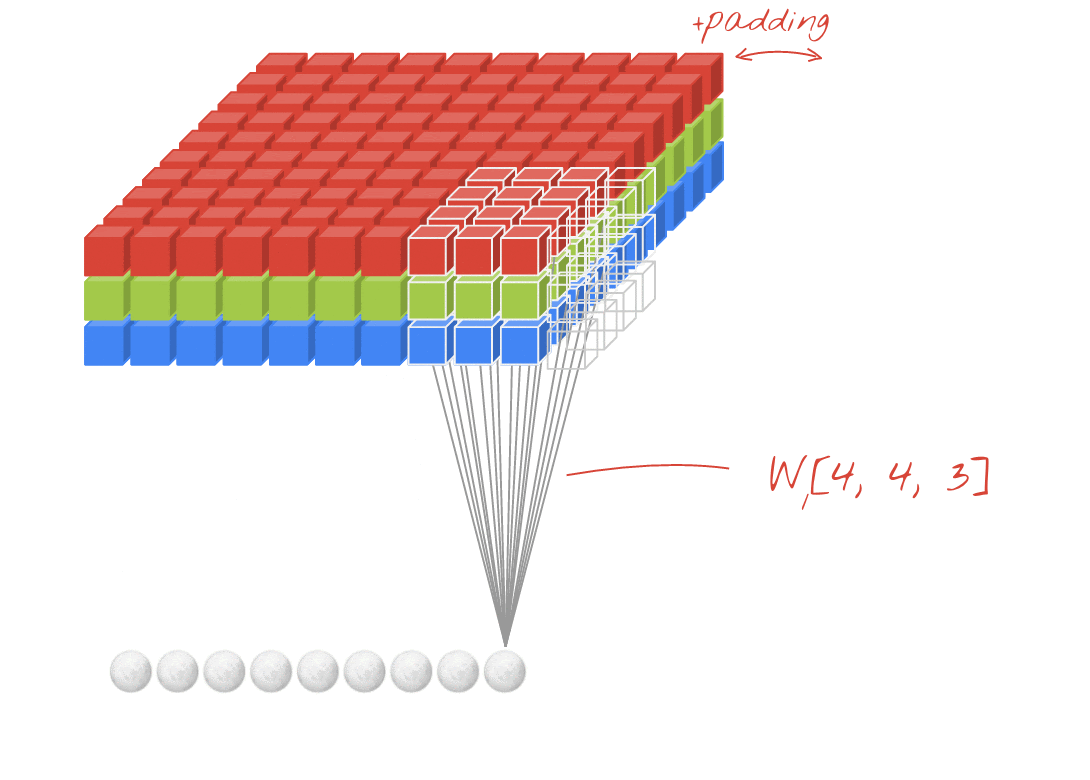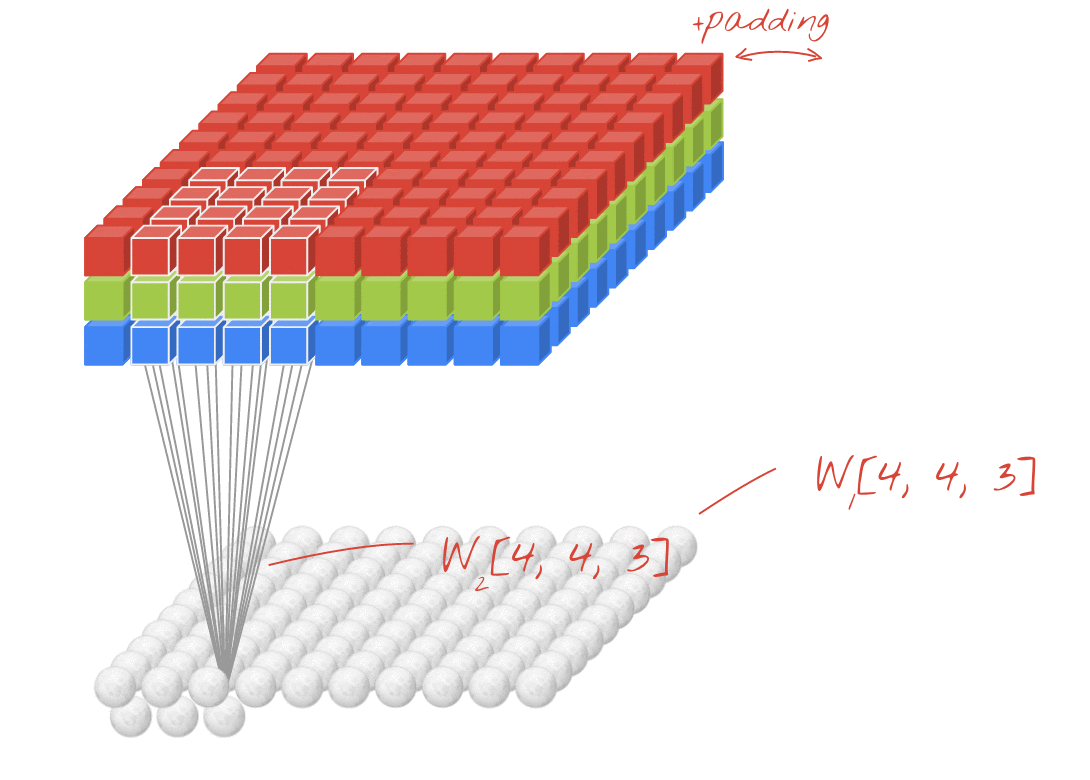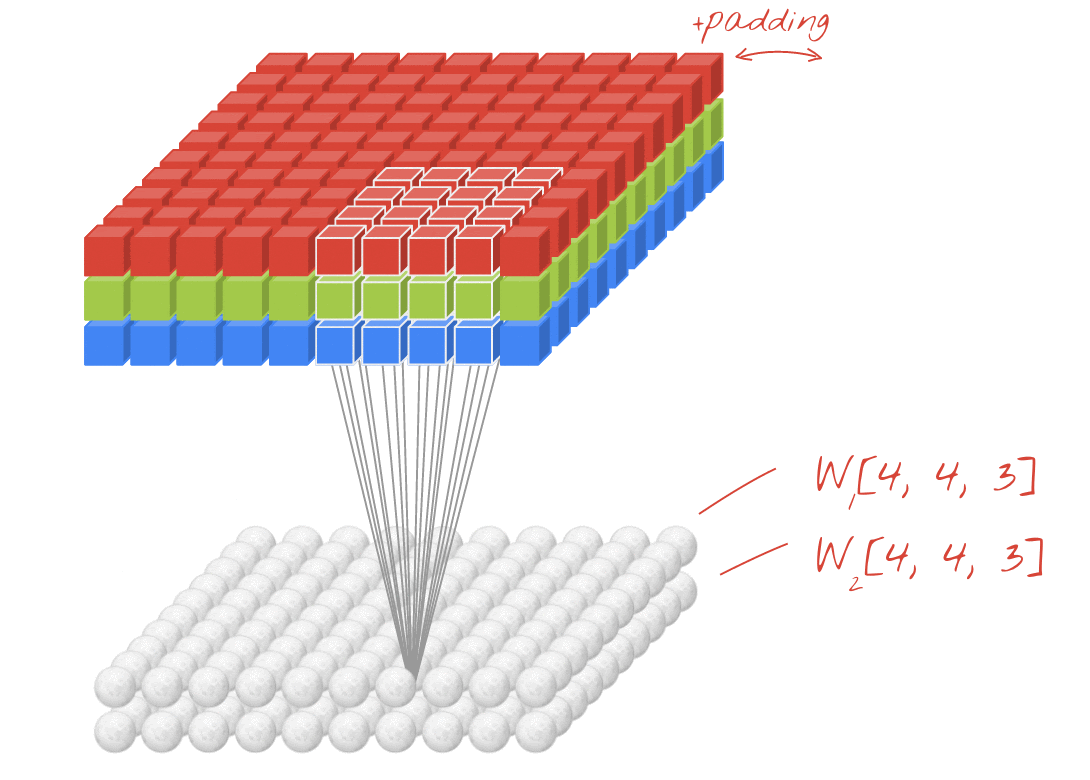
import math
modelo_4 = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28,28,1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu', padding='same'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, activation='relu', padding='same', strides=2),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, activation='relu', padding='same', strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(200, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.666, epoch)
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
modelo_4.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],)
history_m4 = modelo_4.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test),
callbacks=[lr_decay_callback],
batch_size=64, verbose=2)
plot_resultados_modelo(history_m4)

Dropout
As camadas de dropout têm sido o método ideal para reduzir o overfitting de redes neurais

modelo_5 = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28,28,1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu', padding='same'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, activation='relu', padding='same', strides=2),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, activation='relu', padding='same', strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(200, activation='relu'),
tf.keras.layers.Dropout(0.4),
tf.keras.layers.Dense(10, activation='softmax')
])
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.666, epoch)
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
modelo_5.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],)
history_m5 = modelo_5.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test),
callbacks=[lr_decay_callback],
batch_size=64, verbose=2)
plot_resultados_modelo(history_m5)

Batch Normalization
A idéia do Batch Normalization é normalizar a saída das ativações entre cada camada da rede neural. Isso 'redefine' efetivamente a distribuição da saída da camada anterior para ser processada com mais eficiência pela camada subsequente.

modelo_6 = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, use_bias=False, padding='same'),
tf.keras.layers.BatchNormalization(center=True, scale=False),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, use_bias=False, padding='same', strides=2),
tf.keras.layers.BatchNormalization(center=True, scale=False),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, use_bias=False, padding='same', strides=2),
tf.keras.layers.BatchNormalization(center=True, scale=False),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(200, use_bias=False),
tf.keras.layers.BatchNormalization(center=True, scale=False),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(10, activation='softmax')
])
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.666, epoch)
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
modelo_6.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],)
history_m6 = modelo_6.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test),
callbacks=[lr_decay_callback],
batch_size=64, verbose=2)
plot_resultados_modelo(history_m6)

Visualizando Resultados
lista_modelos = [modelo_1, modelo_2, modelo_3, modelo_4, modelo_5, modelo_6]
Realizando Predições Dados de Teste
import numpy as np
lista_results = []
for modelo in lista_modelos:
results = modelo.predict(x_test)
results = np.argmax(results, axis=1)
lista_results.append(results)
Matriz de Confusão
import sklearn
from sklearn.metrics import confusion_matrix
lista_cms = []
for resultado in lista_results:
cm = confusion_matrix(
y_test, resultado, labels=np.arange(10),
)
lista_cms.append(cm)
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(15, 7))
ax = ax.flatten()
for i in range(6):
cm_norm = sklearn.preprocessing.MinMaxScaler().fit_transform(lista_cms[i])
sns.heatmap(cm_norm, cmap='Blues', ax=ax[i]);
ax[i].set_title(f'Modelo {i + 1}')

Gráfico de Barras
from sklearn.metrics import accuracy_score
lista_accs = []
fig, ax = plt.subplots(figsize=(5, 3))
for resultado in lista_results:
acc = accuracy_score(resultado, y_test)
lista_accs.append(acc)
ax.barh(range(6), width=lista_accs, color=['k', 'r', 'gray', 'g', 'y', 'b'], ec='k')
ax.set_yticks([0, 1, 2, 3, 4, 5], ['Modelo 1', 'Modelo 2', 'Modelo 3', 'Modelo 4', 'Modelo 5', 'Modelo 6']);
ax.set_xlim(0.8, 1)
ax.set_xlabel('Acurácia')
ax.set_title('Desempenho dos Modelos');

Encontrando Melhor Modelo com Keras Tuner
Podemos usar a classe KerasTuner para realizar uma pesquisa para encontrar os melhores hiperparâmetros para um modelo de classificação do MNIST usando o TensorFlow.
!pip install keras-tuner
import tensorflow as tf
from tensorflow import keras
from keras import layers
import keras_tuner
from keras_tuner import RandomSearch
Função para Criação do Modelo
# Função para criar o modelo
def constroi_modelo(hp):
model = keras.Sequential()
# Camada vetorização
model.add(layers.Flatten(input_shape=(28, 28, 1)))
# laço para definir quantidade de camadas
for i in range(hp.Int('num_layers', 2, 3)):
model.add(layers.Dense(units=hp.Int(f'units_{i}', 32, 64, 128), activation='relu'))
model.add(layers.Dropout(rate=hp.Float(f'dropout_{i}', 0.1, 0.5, 0.05)))
model.add(layers.Dense(units=10, activation='softmax'))
model.compile(
optimizer=keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
Pesquisando Modelos
# Define o objeto RandomSearch
tuner = RandomSearch(
constroi_modelo,
objective='val_accuracy',
max_trials=15,
executions_per_trial=1,
directory='mnist',
)
# Executa a pesquisa em grade
tuner.search(
x_train,
y_train,
batch_size=128,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tf.keras.callbacks.TensorBoard("mnist2", histogram_freq=1)])
Trial 15 Complete [00h 00m 22s]
val_accuracy: 0.9520999789237976
Best val_accuracy So Far: 0.95660001039505
Total elapsed time: 00h 05m 02s
TensorBoard
%reload_ext tensorboard
%tensorboard --logdir=mnist2
<IPython.core.display.Javascript object>
Exemplos de Visualizações TensorBoard
Histogramas

Distribuição dos Pesos por Camada

Hierparametros

Exercício - Classificação Cifar 10
Repita as tarefas desse laboratório para o dataset Cifar10, o qual é um conjunto de dados amplamente utilizado em tarefas de aprendizado de máquina, especialmente em visão computacional. Ele contém 60.000 imagens coloridas, com tamanho de 32x32 pixels distribuídas em 10 classes diferentes, totalizando 6.000 imagens por classe. As classes incluem categorias comuns, como aviões, automóveis, pássaros, gatos, cervos, cachorros, sapos, cavalos, navios e caminhões.

O dataset é dividido em 50.000 imagens para treinamento e 10.000 imagens para teste, sendo frequentemente utilizado como benchmark para avaliar o desempenho de algoritmos de classificação de imagens. Cada imagem é rotulada com apenas uma classe, o que torna o CIFAR-10 um problema de classificação supervisionada.
Warning
As dimensões das imagens são diferentes e agora possuem 3 canais de cores, portanto as entradas dos modelos vão precisar serem ajustadas!