Federated LLM Fine-tuning
O fine-tuning federado de modelos LLM com Flower e PEFT permite ajustar modelos pré-treinados a dados específicos de cada usuário sem comprometer sua privacidade, já que os dados não são compartilhados entre os clientes. Utiliza-se o PEFT (Parameter-Efficient Fine-Tuning) para otimizar o processo de ajuste fino, reduzindo o uso de recursos por meio de técnicas como quantização em 4-bit e 8-bit, diminuindo assim o consumo de VRAM.
Clonar o repositório :
git clone --depth=1 https://github.com/DinhoVCO/MO809A.git _tmp \
&& mv _tmp/FederatedLLM/FT_lite ./ \
&& rm -rf _tmp \
&& cd FT_lite
1. Import packages and utilities
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
import flwr as fl
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import IidPartitioner
from datasets import load_dataset
from flwr.client.mod import fixedclipping_mod
from flwr.server.strategy import (
DifferentialPrivacyClientSideFixedClipping
)
from utils.utils import *
function 'cadam32bit_grad_fp32' not found
- Load configuration.
cfg = get_config("federated_lite")
2. Dataset partition
partitioner = IidPartitioner(num_partitions=cfg.flower.num_clients)
fds = FederatedDataset(
dataset=cfg.dataset.name,
partitioners={"train": partitioner}
)
partition_zero = fds.load_partition(0)
partition_zero
Dataset({
features: ['input', 'output', 'instruction'],
num_rows: 1698
})
visualize_partitions(fds)

3. Client and Server
- Load the tokenizer and other components.
(
tokenizer,
data_collator,
formatting_prompts_func,
) = get_tokenizer_and_data_collator_and_propt_formatting(
cfg.model.name,
cfg.model.use_fast_tokenizer,
cfg.train.padding_side,
)
- Define the client.
def gen_client_fn(
fds,
tokenizer,
formatting_prompts_func,
data_collator,
model_cfg: DictConfig,
train_cfg: DictConfig,
save_path: str,
) -> Callable[[str], FlowerClient]: # pylint: disable=too-many-arguments
"""Generate the client function that creates the Flower Clients."""
def client_fn(context: Context) -> FlowerClient:
"""Create a Flower client representing a single organization."""
# Let's get the partition corresponding to the i-th client
partition_id = int(context.node_config["partition-id"])
client_trainset = fds.load_partition(partition_id, "train")
client_trainset = client_trainset.remove_columns(["instruction"])
client_trainset = client_trainset.rename_column("input", "instruction")
client_trainset = client_trainset.rename_column("output", "response")
return FlowerClient(
model_cfg,
train_cfg,
client_trainset,
tokenizer,
formatting_prompts_func,
data_collator,
save_path,
).to_client()
return client_fn
Dados privados
Embora o aprendizado federado não compartilhe os dados brutos entre os clientes, apenas intercambie os pesos do modelo, persiste o problema de vazamento de informações em modelos de linguagem grandes (LLMs). Os LLMs tendem a memorizar informações específicas em seus parâmetros durante o processo de treinamento, especialmente quando trabalham com dados sensíveis ou privados. Isso significa que, embora os dados originais não sejam compartilhados explicitamente, os parâmetros ajustados do modelo podem incorporar detalhes que refletem aspectos dos dados privados, representando um potencial risco de privacidade
save_path = "./my_fl_model_dp"
client = fl.client.ClientApp(
client_fn=gen_client_fn(
fds,
tokenizer,
formatting_prompts_func,
data_collator,
cfg.model,
cfg.train,
save_path,
),
mods=[fixedclipping_mod]
)
Privacidade Diferencial
A privacidade diferencial é uma técnica que oferece garantias estatísticas para proteger a informação individual em um conjunto de dados, adicionando ruído aos resultados das análises ou algoritmos. Isso permite fazer inferências úteis em nível de grupo, enquanto oculta as contribuições de dados individuais, garantindo que o resultado não mude significativamente se um único dado for adicionado ou removido. Aplica-se principalmente para proteger dados sensíveis, como os de saúde ou financeiros, evitando que informações pessoais sejam inferidas, mesmo quando combinadas com dados externos ou ataques avançados de reidentificação.
Recorte do lado do cliente
O recorte do lado do cliente é uma técnica no aprendizado federado onde cada cliente aplica localmente um limite na magnitude de seus gradientes antes de enviá-los ao servidor central para agregação. Se os gradientes calculados excedem um limite especificado, eles são escalados para que sua magnitude não ultrapasse esse valor, preservando assim sua direção original. Essa abordagem reduz o risco de vazamento de dados sensíveis e distribui a carga computacional, evitando que o servidor precise recortar as atualizações de todos os clientes. No entanto, exige que o servidor comunique o limite de recorte aos clientes e confie que eles o apliquem corretamente, o que pode introduzir desafios de coordenação e consistência no processo de treinamento.
- Use Differential Privacy
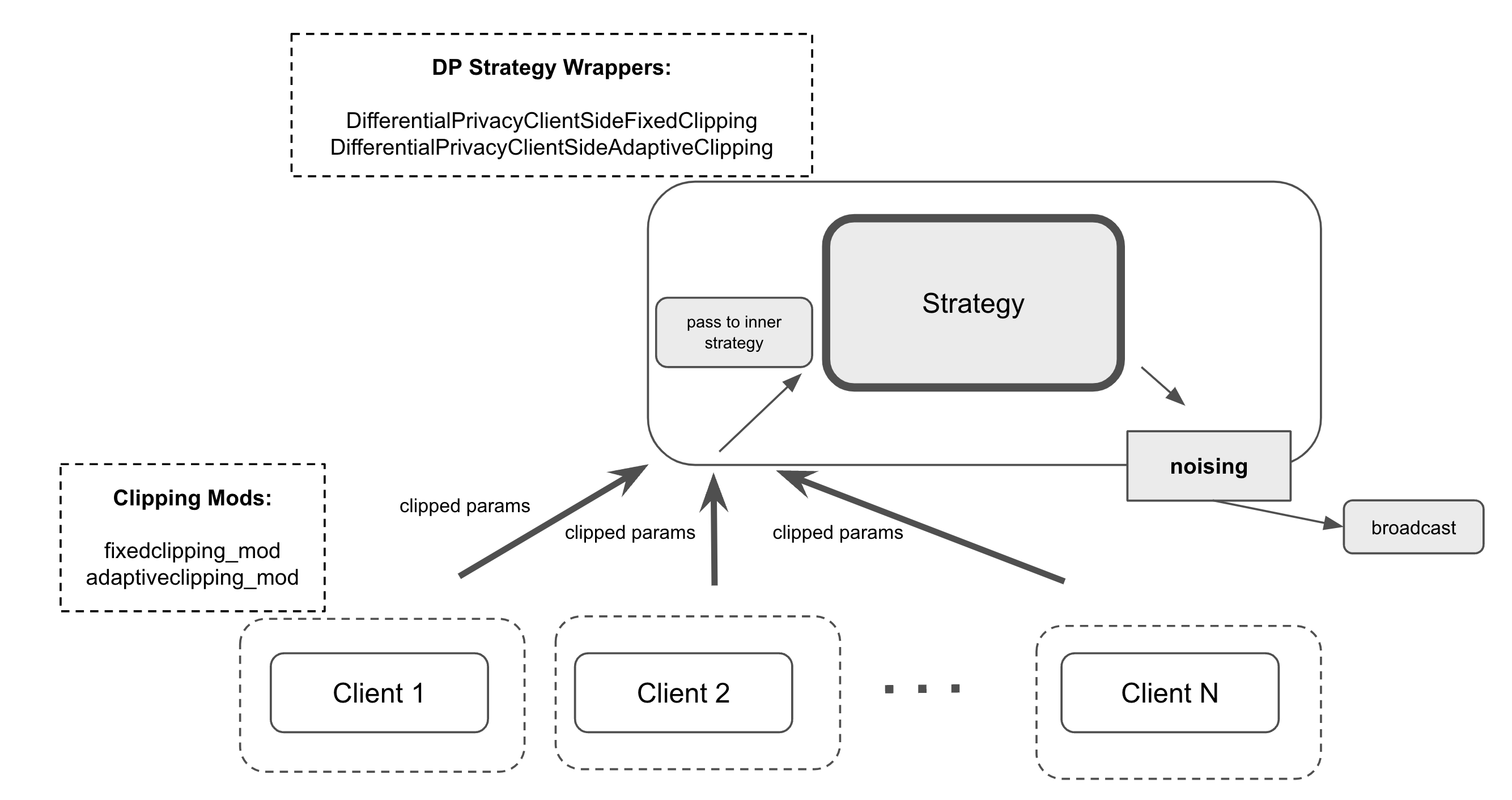
Posteriormente, utiliza-se o mecanismo gaussiano para adicionar ruído com o objetivo de distorcer a soma das atualizações de todos os clientes. A quantidade de ruído é escalada de acordo com o valor da sensibilidade para obter uma garantia de privacidade.
- Define the server function and add Differential Privacy.
def server_fn(context: Context):
# Define the Strategy
strategy = fl.server.strategy.FedAvg(
min_available_clients=cfg.flower.num_clients, # total clients
fraction_fit=cfg.flower.fraction_fit, # ratio of clients to sample
fraction_evaluate=0.0, # No federated evaluation
# A (optional) function used to configure a "fit()" round
on_fit_config_fn=get_on_fit_config(),
# A (optional) function to aggregate metrics sent by clients
fit_metrics_aggregation_fn=fit_weighted_average,
# A (optional) function to execute on the server after each round.
# In this example the function only saves the global model.
evaluate_fn=get_evaluate_fn(
cfg.model,
cfg.train.save_every_round,
cfg.flower.num_rounds,
save_path,
),
)
# Add Differential Privacy
sampled_clients = cfg.flower.num_clients*strategy.fraction_fit
strategy = DifferentialPrivacyClientSideFixedClipping(
strategy,
noise_multiplier=cfg.flower.dp.noise_mult,
clipping_norm=cfg.flower.dp.clip_norm,
num_sampled_clients=sampled_clients
)
# Number of rounds to run the simulation
num_rounds = cfg.flower.num_rounds
config = fl.server.ServerConfig(num_rounds=num_rounds)
return fl.server.ServerAppComponents(strategy=strategy, config=config)
- Instantiate the ServerApp.
server = fl.server.ServerApp(server_fn=server_fn)
4. Run
- Run the simulation.
fl.simulation.run_simulation(
server_app=server,
client_app=client,
num_supernodes=cfg.flower.num_clients,
backend_config={"init_args": backend_setup}
)
[92mINFO [0m: Starting Flower ServerApp, config: num_rounds=10, no round_timeout
[92mINFO [0m:
[92mINFO [0m: [INIT]
[92mINFO [0m: Requesting initial parameters from one random client
[92mINFO [0m: Received initial parameters from one random client
[92mINFO [0m: Starting evaluation of initial global parameters
[92mINFO [0m: initial parameters (loss, other metrics): 0.0, {}
[92mINFO [0m:
[92mINFO [0m: [ROUND 1]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (1, 0.0, {}, 360.854782099952)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 2]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (2, 0.0, {}, 709.8555060999934)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 3]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (3, 0.0, {}, 1045.720024600043)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 4]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (4, 0.0, {}, 1392.9687937999843)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 5]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (5, 0.0, {}, 1692.5614437999902)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 6]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (6, 0.0, {}, 1975.4084746999433)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 7]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (7, 0.0, {}, 2288.747705799993)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 8]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (8, 0.0, {}, 2634.2372885999503)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 9]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (9, 0.0, {}, 2993.517644800013)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [ROUND 10]
[92mINFO [0m: configure_fit: strategy sampled 4 clients (out of 20)
[92mINFO [0m: aggregate_fit: received 4 results and 0 failures
[92mINFO [0m: aggregate_fit: central DP noise with 0.0025 stdev added
[92mINFO [0m: fit progress: (10, 0.0, {}, 3395.479693399975)
[92mINFO [0m: configure_evaluate: no clients selected, skipping evaluation
[92mINFO [0m:
[92mINFO [0m: [SUMMARY]
[92mINFO [0m: Run finished 10 round(s) in 3395.48s
[92mINFO [0m: History (loss, centralized):
[92mINFO [0m: round 0: 0.0
[92mINFO [0m: round 1: 0.0
[92mINFO [0m: round 2: 0.0
[92mINFO [0m: round 3: 0.0
[92mINFO [0m: round 4: 0.0
[92mINFO [0m: round 5: 0.0
[92mINFO [0m: round 6: 0.0
[92mINFO [0m: round 7: 0.0
[92mINFO [0m: round 8: 0.0
[92mINFO [0m: round 9: 0.0
[92mINFO [0m: round 10: 0.0
[92mINFO [0m: History (metrics, distributed, fit):
[92mINFO [0m: {'train_loss': [(1, 3.847695939478722),
[92mINFO [0m: (2, 4.3202722353114416),
[92mINFO [0m: (3, 4.328049072301575),
[92mINFO [0m: (4, 4.4609375),
[92mINFO [0m: (5, 4.136699189985272),
[92mINFO [0m: (6, 4.406222389927846),
[92mINFO [0m: (7, 4.601526836990134),
[92mINFO [0m: (8, 4.390625),
[92mINFO [0m: (9, 5.140622699160653),
[92mINFO [0m: (10, 4.875)]}
[92mINFO [0m:
5. Run the fine-tuned model.
# Load dataset
train_dataset = load_dataset(cfg.dataset.name, split='train')
# Select training example
example_index = 6
data_point = train_dataset[example_index]
prompt = data_point["input"]
prompt
'What are the possible causes of low glucose and high C-peptide levels?'
answer = data_point["output"]
answer
'Low glucose and high C-peptide levels can be caused by an insulinoma or the use of sulfonylurea drugs.'
- Modelo pre-treinado
model, tokenizer = load_pretrained_model(cfg.model.name)
Carregando o tokenizador para EleutherAI/pythia-70m...
Carregando o modelo pré-treinado EleutherAI/pythia-70m...
O modelo foi carregado com sucesso no dispositivo: cpu
answer1 = generate_text(model, tokenizer, data_point["input"], max_length=100)
print(answer1)
What are the possible causes of low glucose and high C-peptide levels?
: The main reason is that there may be a decrease in insulin secretion, which can lead to an increase or even death. In fact it has been suggested by other studies (eurotide et al., [@B31]; Kahnke & Hickman; @Kahler1) for example using serum albumin as well \[[@R32]\]. However this study did not find any significant differences between these two conditions
- Modelo Fine Tuning Federado
#save_path = "./my_fl_model"
lora_adapter_path = f"{save_path}/peft_10/"
# Cargar el modelo combinado con el adaptador LoRA y el tokenizador
model_FL, tokenizer_FL = load_model_with_lora_adapter(cfg.model.name, lora_adapter_path)
Carregando o tokenizador para EleutherAI/pythia-70m...
Carregando o modelo pré-treinado EleutherAI/pythia-70m...
Aplicando o adaptador LoRA de ./my_fl_model_dp/peft_10/...
trainable params: 0 || all params: 70,623,232 || trainable%: 0.0
O modelo combinado com o adaptador LoRA foi carregado com sucesso.
answer2 = generate_text(model_FL, tokenizer_FL, data_point["input"], max_length=100)
print(answer2)
What are the possible causes of low glucose and high C-peptide levels?
Certain questions that can be addressed include: (1) how to use a specific chemical as well for diagnosis, treatment objectives/conditions;(2);and why not. The nature or extent may vary with disease stage in which patients will have at least one clinical reason by including these symptoms during follow up studies on this subject's illness when they were diagnosed because their condition is known if you report any other symptom before your