Instruções: Para essa unidade, você deve ler as seções 5.3 a 5.6 do tutorial Python. Só leia a seção de classes do tutorial depois que estiver confortável com os conceitos de conjuntos e dicionários. Quando se sentir pronto, leia a seção 9 até a subseção 9.4.
Para guardar dados na memória do computador, quase sempre utilizamos variáveis ou listas de variáveis de tipos básicos. Como não tínhamos muitas opções, não nos preocupávamos com a forma com que os dados eram armazenados. Nesta unidade, veremos que as escolhas que fazemos para representar dados na memória têm consequências importantes para os algoritmos que lemos e escrevemos. Essas consequências são percebidas tanto quando queremos dar significado aos dados, quanto quando queremos executar algum algoritmo.
Iremos falar de dois conceitos que devem acompanhar uma programadora durante toda a vida: abstração e representação. Desde que começamos a falar de algoritmos, vimos que preferimos falar de bytes ao invés de bits, de palavras ao invés de sequência de caracteres e assim por diante. Enquanto um computador só manipula dados (ou bits, em última instância), nos nossos algoritmos, preferimos falar de objetos mais próximos do nosso cotidiano. Assim, queremos falar de estudantes, ao invés de um número de RA associado a um nome. Nesse caso, criamos uma abstração para um estudante que é representada em memória por um inteiro e uma string.
O dados que precisamos armazenar para uma determinada abstração dependem do problema. Por exemplo, se queremos descobrir se um estudante foi aprovado, uma prova poderia muito bem ser representada por um número de ponto flutuante correspondente à nota. Se quisermos calcular a nota da prova em si, então provavelmente representaríamos a prova como uma lista de números correspondente às questões. A representação de uma abstração corresponde tanto à lista de dados que armazenamos na memória bem como a forma com que esses dados estão organizados.
Por exemplo, no momento da inscrição em uma universidade, cada estudante precisa preencher um fomulário. Esse formulário é uma tabela padronizada com espaço reservado para vários campos, como nome, data de nascimento, endereço etc. Nesse exemplo, a representação é o leiaute do formulário. Já cada cópia do formulário preenchida corresponde a um objeto ou indivíduo de nossa abstração "estudante". Nem todo conjunto de dados compatível com a representação corresponde a um indivíduo da abstração, afinal, não basta preencher um formulário de inscrição para ser universitário. Similarmente, nem todo trio de números inteiros corresponde a uma data.
Os dados sozinhos não servem para muita coisa se não tivermos o que fazer com eles. Assim, além da forma com que os dados são armazenados, também precisamos de uma lista de operações que permitem acessá-los e modificá-los. De maneira mais ampla, chamamos de estrutura de dados o conjunto de regras e convenções que definem a representação de uma abstração associado a uma lista de operações permitidas.
A primeira vez que utilizamos uma abstração razoavelmente sofisticada e que não fosse um tipo padrão de Python foi quando estudamos matrizes. Naquele momento, representamos uma matriz como uma lista de listas de escalares. Poderíamos também ter representado uma matriz como uma única lista de escalares, lidos da esquerda para direita e de cima para baixo. A razão para escolhermos listas de listas é que essa organização facilita bastante a operação mais comum de uma matriz: acessar um determinado elemento.
A escolha ou o projeto de uma estrutura de dados não é tarefa trivial e não é nosso objetivo aprender a projetar estruturas de dados avançadas — há uma disciplina só para isso. Por enquanto, o que é importante é entender que cada estrutura de dados é projetada para executar bem e eficientemente um conjunto próprio de operações. Assim, para escolher uma estrutura de dados, vamos comparar as operações de que precisamos com as operações que cada estrutura de dados que conhecemos oferece. Isso não é fácil. Não vou mentir.
Coleções dinâmicas de dados
Em diversos dos problemas que queremos resolver com um computador, precisamos lidar com uma grande quantidade de dados. Ter muitos dados implica que que precisamos tratar a maioria deles de maneira uniforme, já que não podemos escrever um algoritmo para cada indivíduo. Assim, vamos imaginar que o conjunto de dados de entrada de nosso problema corresponde a uma coleção que cada elemento dessa coleção é um indivíduo da mesma abstração.
Muitas vezes as coleções de dados são dinâmicas, i.e., elas mudam com o tempo. As operações que podemos fazer sobre coleções dinâmicas são variadas, mas quase sempre queremos pelos menos
- inserir um novo elemento;
- buscar ou alterar um elemento existente;
- remover um elemento existente.
Até então, estudamos coleções dinâmicas bem simples: listas de inteiros, listas de strings, etc. Dessa vez, vamos falar de uma coleção de objetos mais elaborados.
Considere um dicionarista. Ele é responsável estudar e investigar um conjunto de palavras. Ele pode catalogar novas palavras, alterar a definição de palavras existentes... Como representar o dicionário manipulado por ele?
Normalmente, sempre falamos de um problema com entrada e saída bem definidas. Nesse caso, não temos uma entrada nem saída, mas falamos das operações que desejamos realizar com uma coleção de dados. O motivo é que queremos criar uma estrutura de dados que possa ser utilizada pelo dicionarista em diversas situações.
Primeiro, precisamos listar que dados precisamos guardar. Ora, os dados que precismos guardar são as palavras do idioma. O problema é que Python não tem ideia do que é uma palavra — aliás, Python não tem ideia nenhuma, apenas tipos. Podemos dizer então que uma palavra é uma string. Mas isso seria desvalorizar o trabalho do dicionarista, que pesquisa a definição de cada uma palavra. Então vamos guardar também a definição da palavra. Mas e o ano em que a palavra foi catalogada pela primeira vez? Também é importante conhecer a história das palavras.
O fato é que, associado a uma palavra, há um conjunto enorme de outras informações e qualquer subconjunto pequeno de dados que escolhermos não irá representar uma palavra em sua plenitude. Por isso, iremos omitir todos os dados que não interessam à nossa aplicação. Pode ser que esse dicionarista em particular esteja interessado apenas na palavra, na definição e no ano em que ela foi catalogada. Uma palavra e sua definição são facilmente representadas por strings e o ano, é claro, por um inteiro, como 2020. Hum... não seria tão claro assim se você tivesse nascido no milênio passado.
Agora podemos pensar no dicionário. Queremos armazenar uma lista de
palavras, então uma escolha óbvia parece ser uma lista de strings
palavras. Do mesmo modo, criamos uma lista de strings definicoes
para representar as definições e uma lista de inteiros anos para
representar os anos. Portanto, uma palavra palavras[i] teria sido
catalogada no ano anos[i] e assim por diante. Isso é suficiente para
guardar todos os dados de nossa aplicação, mas é uma péssima escolha
de estrutura de dados. O motivo é que uma regra de ouro das estruturas
de dados diz que dados relacionados devem andam juntos. Imagine, por
exemplo, o que acontece se quisermos ordenar a lista de palavras
alfabeticamente. Dá nervoso só de pensar.
Como vimos matrizes recentemente, é tentador remediar a situação e
dizer que devemos representar um dicionário como uma matriz dos dados.
Afinal, o que queremos representar é uma tabela de dados. Digamos
então que dicionario é uma matriz, isso é, uma lista de listas. Isso
é definitivamente muito melhor do que a representação anterior, mas
tampouco é uma boa escolha. Uma razão é que chamamos de matriz uma
estrutura bidimensional de dados escalares do mesmo tipo, mas um
inteiro representando um ano é bem distinto de uma string
representando uma definição. Outra razão é que não é claro o que
significa uma entrada da matriz dicionario[i][j]. Seria o j-ésimo
dado da i-ésima palavra, ou seria o i-ésimo dado da j-ésima
palavra? Em uma matriz, não há motivo nenhum para preferir uma forma a
outra.
Na verdade, um dicionário é uma coleção de verbetes, então seria muito melhor representá-lo como uma lista de verbetes — mas, ao contrário de uma palavra que pode ser facilmente representada por uma string, não há tipo nativo em Python que corresponda a um verbete. Isso sugere que devamos criar nossa própria abstração para representar um verbete. Um verbete consiste de exatamente três dados distintos, a palavra, a definição e o ano, então é natural representá-lo como uma tupla:
(palavra, definição, ano)
Uma tupla é parecida com a uma lista, mas não podemos adicionar ou
remover elementos, nem mudar os objetos a que ela se refere.
Poderíamos dizer também que um verbete é uma lista
[palavra, definicao, ano], mas há algumas vantagens em utilizar uma
tupla. Como a tupla é imutável, comunicamos claramente que há três, e
só três, dados em um verbete. Também, como já discutimos, preferimos
trabalhar com listas cujos elementos tenham o mesmo tipo e o mesmo
significado. O fato de não podermos modificar os objetos a que uma
tupla se refere pode ser uma desvantagem, mas é uma vantagem nesse
exemplo: não queremos que um verbete lido seja alterado pelo seu
usuário (da mesma forma que não queremos adulterar os livros
emprestados de uma biblioteca).
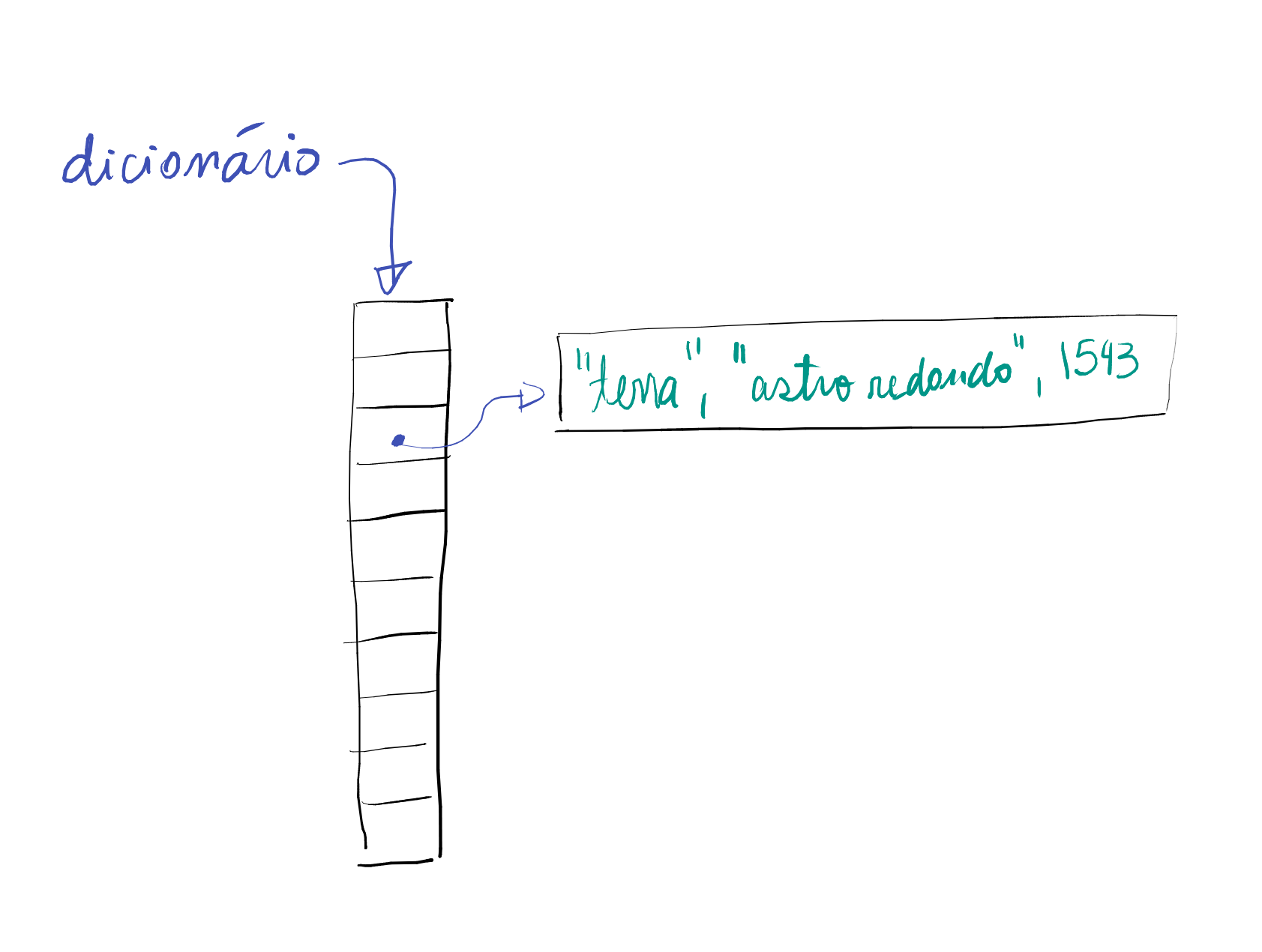
Para deixar o exemplo um pouco mais concreto e para exemplificar como o dicionarista poderia utilizar a estrutura de dados, suponha que ele deseja fazer uma sequencia de operações que inclui criar um dicionário, adicionar um verbete, buscar um verbete e alterar a definição de um verbete.
def main(): dicionario = criar_dicionario() verbete = ("amor", "fogo que arde sem se ver", 1595) adicionar_verbete(dicionario, verbete) verbete = procurar_verbete(dicionario, "amor") palavra, definicao, ano = verbete print(f"{palavra} significa {definicao}") nova_definicao = input("O que você acha que é o amor?\n") atualizar_definicao(dicionario, "amor", nova_definicao) palavra, definicao, ano = procurar_verbete(dicionario, "amor") print(f"{palavra} agora significa {definicao}")
Primeiro, vamos nos concentrar em criar um dicionário e adicionar um verbete.
def criar_dicionario(): """cria um dicionário vazio""" return [] def adicionar_verbete(dicionario, verbete): """adiciona um novo verbete ao dicionário""" dicionario.append(verbete)
Pode parecer bobagem criar uma função apenas pare devolver uma lista
vazia, ou só para adicionar em elemento no final da lista, mas não é.
Mesmo programadores experientes podem dizer que bastaria ter criado
uma lista vazia na função main. Não dê ouvido a eles. Há algumas
razões importantes para termos criado essas funções. Por exemplo, é
mais claro escrever dicionario = criar_dicionario() para dizer que
estamos criando um novo indivíduo da abstração "dicionário" do que
escrever dicionario = []. Mais importante do que isso, quando
escrevemos dicionario = [], temos que nos preocupar em como um
dicionário está representado na memória, mas é exatamente isso que
nossa abstração está tentando esconder.
Vamos agora implementar a busca e a atualização de um verbete.
def procurar_verbete(dicionario, palavra): """devolve o verbete correspondente à palavra; se palavra não for encontrada, devolve None""" for verbete in dicionario: if verbete[0] == palavra: return verbete return None def atualizar_definicao(dicionario, palavra, nova_definicao): """atualiza a definição de uma palavra""" for verbete in dicionario: if verbete[0] == palavra: verbete[1] = nova_definicao
Na função procurar_verbete, usamos None, que é um valor especial
em Python para representar ausência. Mas a implementação acima está
errada. O motivo é que não podemos alterar tuplas. Você pode pensar
nisso como uma desvantagem, mas imagine se alguma outra função tivesse
um verbete e o alterasse ignorando que ele é parte do dicionário. Essa
função estaria alterando o dicionário, então qualquer outra função que
buscasse por esse verbete no dicionário iria ser afetada pela
alteração. Muito provavelmente, isso causaria um bug muito difícil de
encontrar. Para poder atualizar o dicionário então, precisamos
substituir o verbete por um novo, mas para alterar um elemento
referenciado por uma lista, precisamos do índice correspondente.
def procurar_indice(dicionario, palavra): """devolve o índice correspondente à palavra ou None se ela não existir no dicionário""" for i, verbete in enumerate(dicionario): if verbete[0] == palavra: return i return None def atualizar_definicao(dicionario, palavra, nova_definicao): """atualiza a definição de uma palavra""" i = procurar_indice(dicionario, palavra) verbete_antigo = dicionario[i] verbete_novo = (verbete_antigo[0], nova_definicao, verbete_antigo[2]) dicionario[i] = verbete_novo
Para o interpretador Python, dicionario é só mais uma lista, então
ele não se importaria se o dicionarista escrevesse a função abaixo.
def main(): dicionario = criar_dicionario() verbete = ("amor", "fogo que arde sem se ver", 1595) adicionar_verbete(dicionario, verbete) outro = ("amor", "é sofrer amargamente", 2020) adicionar_verbete(dicionario, outro) palavra, definicao, _ = procurar_verbete(dicionario, "amor") print(f"{palavra} significa {definicao}")
Teríamos um dicionário com dois verbetes correspondendo à mesma
palavra. Não parece algo muito confiável: quando alguém procurar por
uma palavra, qual definição seria devolvida? Nesse caso, a função
procurar_verbete percorre a lista do início ao fim, então ela
devolveria a primeira definição. Uma outra implementação poderia
devolver a segunda definição e ainda assim cumprir o combinado em sua
documentação.
user@notebook:~/ra123456/colecoes$ python3 dicionario_tuplas.py amor significa fogo que arde sem se ver
Onde está o erro? Deve estar na função procurar_verbete, ou na
função main. Nesse caso, está na função main, então o dicionarista
deveria certificar-se de que a palavra não está no dicionário antes de
adicioná-la. Mas isso é pedir demais a ele. A função que realmente
deixou a nossa representação na memória inconsistente foi
adicionar_verbete. Seria muito bom se, quando o dicionarista
tentasse adicionar um verbete para uma palavra existente, o
informássemos desse erro.
def adicionar_verbete(dicionario, verbete): """adiciona um novo verbete ao dicionário""" i = procurar_indice(dicionario, verbete[0]) if i is None: dicionario.append(verbete) else: raise Exception(f"Palavra {verbete[0]} já existe.")
Há mais uma novidade aqui. A instrução raise Exception(...) serve
para criar uma nova exceção sinalizando um erro. Já lidamos com
exceções antes; o que há de diferente aqui é que, dessa vez, nós
criamos nosso próprio erro. Assim, quando o dicionarista executar a
função main com problemas, a execução do programa será interrompida
no momento em que ele tentasse adicionar um verbete para uma palavra
que já está no dicionário.
user@notebook:~/ra123456/colecoes$ python3 dicionario_tuplas.py Traceback (most recent call last): File "dicionario_tuplas.py", line 69, in <module> main() File "dicionario_tuplas.py", line 53, in main adicionar_verbete(dicionario, outro) File "dicionario_tuplas.py", line 14, in adicionar_verbete raise Exception(f"Palavra {verbete[0]} já existe.") Exception: Palavra amor já existe.
Há vários tipos de exceção, como ValueError, IndexError,
ZeroDivisionError e podemos criar a nossa própria hierarquia de
tipos. Nesta disciplina é suficiente utilizar um tipo de erro genérico
e levantar uma exceção. Para isso, basta fazer uma chamada a
Exception passando a mensagem de erro como argumento. Você deveria
ter se convencido de que criar uma função apenas para adicionar um
elemento à lista não é tão bobo assim.
Uma operação sobre a qual não discutimos é a remoção de um verbete. Pode ser que uma palavra se torne obsoleta, então, embora incomum, essa é uma operação que o dicionarista desejaria realizar. Implemente a operação para remover um verbete.
Conjuntos
Em uma lista, temos uma sequência de elementos, ou seja, existe a noção de primeiro elemento, de segundo etc. Enquanto lista é o tipo em Python mais comum para representar coleções de dados, muitas vezes a ordem em que eles estão armazenados é irrelevante. Isso acontece quando falamos de conjuntos, no sentido matemático: não existe uma ordem dos elementos e nenhum elemento aparece mais do que uma vez.
Escreva uma função que receba dois conjuntos de strings e devolva a diferença entre esses conjuntos.
Não é muito difícil escrever um algoritmo para esse problema e depois programá-lo.
def calcular_diferenca(a, b): """recebe conjuntos a e b e devolve a - b""" diferenca = [] for elemento_a in a: if elemento_a not in b: diferenca.append(elemento_a) return diferenca def main(): a = ["ana", "maria", "pedro", "raul"] b = ["sérgio", "gustavo", "maria", "ana"] diferenca = calcular_diferenca(a, b) print(diferenca)
Esse é só um exemplo. Não precisávamos de um computador para descobrir
que a diferença desses conjuntos corresponde a ["pedro", "raul"]. Os
computadores são mais úteis quando trabalhamos com grandes volumes de
dados.
Você já deve ter ouvido falar que português e espanhol são muito parecidos. É bem possível que você entenda uma pessoa falando espanhol — se ela falar bem devagar, mesmo que nunca tenha estudado o idioma. Vamos tirar isso a prova e calcular a diferença das 1000 palavras mais comuns dos dois idiomas.
Primeiro, com um pouco de paciência, precisamos encontrar duas listas
razoavelmente confiáveis de palavras frequentes em português e
espanhol. Você pode achar dois arquivos pt_br.txt e es.txt
aqui. Vamos
investigar um pouco esses arquivos de texto olhando para as primeiras
linhas.
user@notebook:~/ra123456/colecoes$ ls -lh *.txt -rw-rw-r-- 1 user user 6,6M set 25 2013 es.txt -rw-rw-r-- 1 user user 4,8M set 25 2013 pt_br.txt user@notebook:~/ra123456/colecoes$ head pt_br.txt que 3097124 não 2582821 o 2582602 de 2075204 a 1948955 é 1786757 você 1513922 e 1508432 eu 1416433 um 1197384 user@notebook:~/ra123456/colecoes$ head es.txt de 3405234 que 3349162 no 3166057 a 2368719 la 2288023 el 1922428 y 1774259 es 1729448 en 1640089 lo 1429314
O comando head mostra as primeiras dez linhas de um arquivo. Você
não quer abrir um arquivo com vários megabytes em um editor de textos,
acredite. Agora podemos fazer um programa que leia as palavras mais
frequêntes de cada idioma e calcule a diferença.
def ler_palavras_frequentes(nome_arquivo, n): """lê o arquivo de frequência de palavras e devolve as n palavras mais frequentes""" lista = [] with open(nome_arquivo) as arquivo: i = 0 for linha in arquivo: palavra, frequencia = linha.strip().split() lista.append(palavra) i += 1 if i == n: break return lista def calcular_diferenca(a, b): """recebe conjuntos a e b e devolve a - b""" diferenca = [] for elemento_a in a: if elemento_a not in b: diferenca.append(elemento_a) return diferenca def mostrar_lista(lista): for elemento in lista: print(elemento) def main(): n = 10 palavras_es = ler_palavras_frequentes('es.txt', n) palavras_pt_br = ler_palavras_frequentes('pt_br.txt', n) diferenca = calcular_diferenca(palavras_es, palavras_pt_br) mostrar_lista(diferenca) main()
Para testar, começamos comparando as 10 palavras mais frequentes de cada idioma.
user@notebook:~/ra123456/colecoes$ python3 diferenca.py no la el y es en lo
Bueno. Não há tanta interseção assim com as 10 palavras mais
frequentes do espanhol, então precisamos de fato aprender quase todas.
O lado bom é que são palavras fáceis. Vamos contar quantas palavras
novas precisamos aprender se quisermos conhecer as 1000 mais
frequentes do espanhol. Como só estamos interessados na contagem,
vamos substituir a instrução mostrar_lista(diferenca) por algo como
print(f"Queremos aprender {len(diferenca)} palavras."). Executando
para n = 1000, obtemos a saída quase que imediatamente.
user@notebook:~/ra123456/colecoes$ python3 diferenca.py Queremos aprender 742 palavras.
Pelo menos não são todas as 1000 palavras. Para alguém que nasceu
antes dos computadores se popularizarem, parece um grade feito
calcular a diferença entre conjuntos de 1000 palavras em tão pouco
tempo — em algumas dezenas de milissegundos. Para quem já nasceu com
um computador na mão, isso não tem nada de impressionante. Vamos
tentar com 100.000 palavras. Alteramos a função fazendo n = 100000,
salvamos e executamos novamente. Execute você mesmo, não acredite em
tudo que lê!
user@notebook:~/ra123456/colecoes$ python3 diferenca.py Queremos aprender 57529 palavras.
No meu computador, essa execução levou cerca de um minuto e meio! Isso é muito tempo para os padrões atuais. Então precisamos parar e pensar: por que o programa gastou tanto tempo? Será que os computadores de hoje em dia não são rápidos para um problema desse tipo? Com certeza você já viu tarefas muito mais complicadas serem realizadas por um computador em muito menos tempo, então temos que desconfiar de nosso algoritmo.
Quando estamos numa situação como essa, temos que descobrir quais
instruções de nosso programa são executadas mais vezes. Revise o
programa e tente descobrir quais instruções são executadas mais vezes.
Você deve se convencer de que uma delas é a instrução in na linha
que contém if elemento not in b:. Essa instrução é executada 100.000
vezes, uma vez para cada palavra frequente em espanhol. Mas meu
computador executa milhões de instruções elementares por segundo,
então para realmente entender porque o programa gastou tanto tempo
vamos reescrever essa linha explicitando o que o interpretador python
tem que fazer sempre que a executa.
def calcular_diferenca(a, b): """recebe conjuntos a e b e devolve a - b""" diferenca = [] for elemento_a in a: encontrou = False for elemento_b in b: if elemento_a == elemento_b: encontrou = True break if not encontrou: diferenca.append(elemento_a) return diferenca
Como representamos o conjunto de palavras usando uma lista, para encontrar uma determinada palavra na lista, temos que percorrê-la desde o início, não há outro jeito. Pior, no nosso exemplo, em 57.529 da vezes que procuramos alguma palavra, tivemos que percorrer toda a lista de palavras em português, só para descobrir que a palavra em espanhol não estava ali.
A escolha da representação do nosso conjunto de dados nesse caso teve
um impacto tremendo no tempo de execução do algoritmo. Listas foram
feitas para armazenar conjuntos de dados que são acessados
sequencialmente na ordem armazenada --- elas não são boas para
procurar valores arbitrários. Por esse motivo, existe um outro tipo de
coleção de dados para representar conjuntos, o set. A vocação de uma
coleção do tipo set é verificar pertinência eficientemente, então
essa é uma escolha de estrutura de dados ideal para nosso algoritmo.
Vamos criar uma implementação alternativa de nosso programa, dessa
vez usando conjuntos.
def ler_palavras_frequentes(nome_arquivo, n): """lê o arquivo de frequência de palavras e devolve as n palavras mais frequentes""" conjunto = set() with open(nome_arquivo) as arquivo: i = 0 for linha in arquivo: palavra, _ = linha.strip().split() conjunto.add(palavra) i += 1 if i == n: break return conjunto def calcular_diferenca(a, b): """recebe conjuntos a e b e devolve a - b""" diferenca = [] for elemento_a in a: if elemento_a not in b: diferenca.append(elemento_a) return diferenca def mostrar_conjunto(conjunto): for elemento in conjunto: print(elemento) def main(): n = 100000 palavras_es = ler_palavras_frequentes("es.txt", n) palavras_pt_br = ler_palavras_frequentes("pt_br.txt", n) diferenca = calcular_diferenca(palavras_es, palavras_pt_br) # mostrar_conjunto(diferenca) print(f"Queremos aprender {len(diferenca)} palavras.") main()
As funções para manipular conjuntos são ligeiramente diferentes das funções de lista, mas não é difícil se acostumar. Executando, devemos obter a mesma resposta -- o algoritmo é o mesmo, só mudamos a escolha da estrutura de dados.
user@notebook:~/ra123456/colecoes$ python3 diferenca_conjuntos.py Queremos aprender 57529 palavras.
A resposta é mostrada em pouco menos de 150ms, quase não dá pra
perceber. Essa é uma diferença espetacular! Dessa vez escolhemos uma
estrutura de dados mais adequada às operações de que nosso algoritmo
necessita. O motivo para essa diferença é que a representação dos
dados quando armazenamos um conjunto é cuidadosamente pensada para
executar a operação in eficientemente. Nós não estudaremos essa
representação aqui, há toda uma disciplina dedicada a essas questões.
Uma pergunta deve inquietar quem sempre usou o tipo list e aprendeu
que existe o tipo set: se a operação in em uma variável do tipo
conjunto é tão mais rápida, por que não usamos set sempre? A
resposta é que, embora ambos tipos sirvam para armazenar conjuntos de
dados, eles são abstrações diferentes. Quando utilizamos uma lista, a
ordem em que os elementos são armazenados é importante. Quando
utilizamos um conjunto, abrimos mão dessa informação para construir
uma representação mais eficiente para o operador in.
Uma última palavra: além da operação in, o tipo set permite
diversas outras operações sobre os conjuntos. Consulte a documentação
do Python e experimente utilizar várias delas. Em particular,
poderíamos fazer a diferença de conjuntos usando simplesmente o
operador -. Por exemplo, faça o seguinte.
>>> a = {1, 3, 7, 2} >>> b = {7, 1, 8} >>> a - b {2, 3}
Dicionários
Agora vamos mudar um pouco e falar de números.
Crie um programa que calcule o histograma de uma lista de números inteiros.
Primeiro precisamos relembrar o que é um histograma. Um histograma sobre uma dada lista de elementos é uma tabela de contagem que associa cada elemento distinto ao número de vezes que ele aparece na lista. Quando estamos falando de superconjuntos (conjuntos que permitem a repetição de elementos), o número de vezes também é chamado de multiplicidade.
Esse problema parece muito simples. De fato, não é muito difícil escrever um algoritmo para ele.
-
Para cada número $n$ da entrada:
a) se $n$ não apareceu ainda:
- faça a multiplicidade de $n$ receber $1$
- armazene a contagem de $n$
b) se $n$ já apareceu:
- encontre a contagem de $n$
- incremente a multiplicidade de $n$
Pare que esse algoritmo esteja bem definido de fato, antes precisamos dizer como vamos armazenar os números e as multiplicidades. Vimos que para escrever um bom algoritmo, é fundamental pensar com cuidado na representação dos dados que utilizaremos. Queremos guardar os números, então uma lista de números é sempre uma opção. Como não estamos preocupados com a ordem em que os números são armazenados e no nosso algoritmo precisamos determinar repetidamente se um dado número está na nossa coleção , utilizar um conjunto parece uma escolha muito melhor.
Acontece que também queremos guardar os dados relativos à multiplicidades. Poderíamos pensar em uma lista ou em um conjunto de multiplicidades, mas como descobriríamos a qual número se refere cada multiplicidade? Além disso, já sabemos que dados relacionados devem andar juntos. Então queremos criar alguma abstração que associe um número à sua multiplicidade. Digamos que uma contagem é uma lista com dois elementos.
contagem = [número, multiplicidade]
A maneira com que utilizamos uma lista aqui não é muito usual, afinal os dois elementos são do mesmo tipo, mas têm significados bem diferentes. Como a contagem de um número muda no decorrer do algoritmo (e não queremos recriar a contagem cada vez que reencontrarmos um número), utilizar uma lista dessa maneira nesse caso traz mais vantagens do que desvantagens.
Agora, voltamos a pergunta de como representar um histograma. Uma boa
tentativa seria um conjunto de contagens, já que nosso algoritmo
precisa acessar uma contagem rapidamente. Mas isso tem um
problema. Quando estamos percorrendo a lista de entrada e encontramos
um número, queremos atualizar a multiplicidade desse número, mas não
há como acessar o par [número, multiplicidade] diretamente. Temos
que que percorrer cada par de contagem até encontrarmos a contagem
correspondente. Para entender isso, tente descobrir qual a saída
do trecho abaixo.
conjunto = {[1, 100], [7, 21], [3, 45], [2,200]} if 7 in histograma: print('O número 7 está no conjunto') else: print('O número 7 não está no conjunto')
Claro que o número não está no conjunto. A variável referenciada por
conjunto é do tipo set e contém elementos do tipo lista; não há
nenhum número nesse conjunto. Como não há nenhuma vantagem em usar
conjuntos nesse exemplo, vamos utilizar listas, já que estamos mais
familiarizados com elas. Assim, vamos representar um histograma como
uma lista de contagens.
Com isso, podemos implementar o algoritmo acima.
def calcular_histograma(lista_numeros): histograma = [] for numero in lista_numeros: for par in histograma: if par[0] == numero: par[1] += 1 break else: par = [numero, 1] histograma.append(par) return histograma def mostrar_histograma(histograma): for numero, multiplicidade in histograma: print(f"Multiplicidade de {numero}: {multiplicidade}") def main(): lista_numeros = [1, 2, 7, 3, 2, 2, 6, 2, 1, 6] histograma = calcular_histograma(lista_numeros) mostrar_histograma(histograma) main()
Testando o programa para essa entrada pequena, parece tudo certo. O
que acontece quando o conjunto de dados é grande é que é interessante.
Vamos testar com um conjunto de 100.000 números, distribuídos entre 0
e 9999. Dessa vez, vamos usar alguns números aleatórios. Para
descobrir como criar esse arquivo, faça o exercício correspondente ao
módulo random aqui.
user@notebook:~/ra123456/colecoes$ ls -lh muitos.txt -rw-rw-r-- 1 user user 478K jun 13 22:46 muitos.txt user@notebook:~/ra123456/colecoes$ head muitos_numeros.txt 15962 10902 8314 14623 3304 4029 12455 3304 19918 8353
Adaptamos o programa para ler o arquivo.
def ler_arquivo(nome_arquivo): with open(nome_arquivo) as arquivo: lista_numeros = [] for linha in arquivo: numero = int(linha) lista_numeros.append(numero) return lista_numeros def main(): lista_numeros = ler_arquivo("muitos.txt") histograma = calcular_histograma(lista_numeros) mostrar_histograma(histograma)
Executamos e esperamos cerca de 15 segundos para o programa terminar.
Nada surpreendente. Já sabemos que a estrutura de dados utilizada para
representar os dados não é muito boa para as operações de que nosso
algoritmo precisa. Veremos que Python tem uma estrutura de dados
chamada dict, ou tipo dicionário, que é especialmente adequada para
nosso algoritmo. Antes de introduzir dicionários, vamos resolver uma
versão bem mais simples do problema. A esperança é que esse exercício
mais simples nos dê uma intuição sobre qual seria a estrutura de dados
ideal.
Crie um programa que calcule o histograma de uma lista de números inteiros entre 0 e 9999.
Esse é quase o mesmo problema, mas agora podemos supor que todos os números da entrada estão nesse intervalo. Isso sugere que podemos guardar as multiplicidades dos números em um vetor de 10000 posições: os números da entrada correspondem a índices desse vetor. Isso é conveniente pois podemos acessar o dado associado a cada número diretamente!
def ler_arquivo(nome_arquivo): with open(nome_arquivo) as arquivo: lista_numeros = [] for linha in arquivo: numero = int(linha) lista_numeros.append(numero) return lista_numeros def calcular_histograma_simplificado(lista_numeros): histograma = [0] * 10000 for numero in lista_numeros: histograma[numero] += 1 return histograma def mostrar_histograma(histograma): for numero, multiplicidade in enumerate(histograma): print(f"Multiplicidade de {numero}: {multiplicidade}") def main(): lista_numeros = ler_arquivo("muitos.txt") histograma = calcular_histograma_simplificado(lista_numeros) mostrar_histograma(histograma) main()
Observe atentamente como utilizamos cada número como um índice do vetor. Dessa vez, o programa gastou cerca de 70ms para calcular o histograma de 100.000 números. Acessar um índice de uma lista é muito rápido! Para que isso tenha dado certo, foram fundamentais algumas propriedades do problema simplificado.
-
os elementos de entrada que queremos armazenar são números;
-
esses números estão no intervalo de 0 a 9999.
Esse tipo de representação não funciona para o problema geral porque podemos querer calcular histogramas de conjuntos de dados não numéricos. Por exemplo, se quisermos criar um arquivo das palavras mais frequentes de um idioma, o que estamos fazendo na verdade é um histograma de palavras. Mesmo que os dados sejam números inteiros, pode ser que esses números sejam muito grandes. Não queremos criar um vetor que ocupa vários gigabytes de memória apenas para computar um histograma.
Agora já podemos descrever o que queremos de uma estrutura de dados para representar um histograma:
-
queremos armazenar um conjunto de pares
(chave, valor)de forma que cada chave só apareça uma vez no conjunto; -
queremos decidir se uma determinada chave está na coleção, independentemente do valor associado;
-
queremos modificar o valor associado a uma chave rapidamente, assim como modificamos o valor associado a um índice de uma lista.
Uma estrutura de dados que satisfaz todos esses requisitos é um dict.
Vejamos alguns exemplos.
>>> idades = dict() >>> idades["Ana"] = 18 >>> idades["João"] = 17 >>> idades["Mariana"] = 18 >>> idades["Mariana"] = 19 >>> idades {'Ana': 18, 'João': 17, 'Mariana': 19} >>> tipos_triangulos = { ... (3, 3, 3): "equilátero", ... (2, 1, 2): "isósceles", ... (2, 2, 1): "isósceles", ... (3, 4, 5): "escaleno", ... } >>> tipos_triangulos {(3, 3, 3): 'equilátero', (2, 1, 2): 'isósceles', (2, 2, 1): 'isósceles', (3, 4, 5): 'escaleno'} >>> (5,5,5) in tipos_triangulos False >>> (5,4,3) in tipos_triangulos False >>> tipos_triangulos[(5,5,5)] = "equilátero" >>> (5,5,5) in tipos_triangulos True
Veja o trecho acima com cuidado e, se tiver dúvidas sobre a sintaxe,
consulte o tutorial Python. Na primeira linha, a atribuição
idades = dict() cria um dicionário vazio e associa ao nome idades.
Poderíamos escrever apenas idades = {}, mas preferi escrever
dict() para explicitar que estamos criando um dicionário. Com isso,
já podemos ajustar nossa função para calcular histogramas.
def calcular_histograma(lista): histograma = {} for elemento in lista: if elemento not in histograma: histograma[elemento] = 1 else: histograma[elemento] += 1 return histograma def mostrar_histograma(histograma): for elemento, multiplicidade in histograma.items(): print(f"Multiplicidade de {elemento}: {multiplicidade}")
Repare que para percorrer os pares (chave, valor) de um dicionário,
chamamos a função items. Se não tivéssemos usado essa função,
iríamos iterar apenas sobre as chaves. Executamos a versão atualizada
do programa com o arquivo de 100.000 inteiros. Ela gasta cerca de 70ms
apenas e ainda funciona com entradas arbitrárias.
Registros e mutabilidade
Agora que já conhecemos o tipo dicionário, podemos repensar a
representação de um verbete do nosso primeiro exemplo. Lá, dissemos
que um verbete era uma tupla da forma (palavra, definição, ano). Há
algumas desvantagens em se utilizar uma tupla dessa maneira. A
principal delas é que para acessar uma dado associado ao verbete
precisamos utilizar um índice numérico que não tem nada a ver com o
significado daquele dado.
Por exemplo, na nossa representação, a definição de uma palavra é
verbete[1], mas se tivéssemos abstraído um verbete como uma tupla da
forma (palavra, ano, definição), deveríamos escrever verbete[2].
Pior, se algum dia quisermos adicionar outro dado associado a um
verbete, então teremos que revisitar todos os trechos de código que
lidam com a representação de um verbete! Digamos que depois de um
tempo decidamos armazenar juntamente com um verbete a classe associada
a determinada palavra (substantivo, adjetivo, etc.). Atualizamos a
representação de um verbete para uma tupla da forma
(palavra, classe, definição, ano).
def atualizar_definicao(dicionario, palavra, nova_definicao): """atualiza a definição de uma palavra""" i = procurar_indice(dicionario, palavra) verbete_antigo = dicionario[i] verbete_novo = (verbete_antigo[0], verbete_antigo[1], nova_definicao, verbete_antigo[3]) dicionario[i] = verbete_novo def main(): dicionario = criar_dicionario() verbete = ("amor", "substantivo", "fogo que arde sem se ver", 1595) adicionar_verbete(dicionario, verbete) verbete = procurar_verbete(dicionario, "amor") palavra, classe, definicao, ano = verbete print(f"{palavra} significa {definicao}") nova_definicao = input("O que você acha que é o amor?\n") atualizar_definicao(dicionario, "amor", nova_definicao) palavra, definicao, ano = procurar_verbete(dicionario, "amor") print(f"{palavra} agora significa {definicao}")
Tivemos que alterar praticamente toda a função main, já que ela cria
e manipula os verbetes. O que foi desagradável é que tivemos que
alterar também a função atualizar_definicao, mesmo que a definição
não tenha nada a ver com a classe da palavra. Sempre que mudamos a
representação em memória de uma certa abstração precisamos revisar
todas as instruções que acessam essa representação diretamente.
Aff... esqueci de atualizar as variáveis recebidas na última chamada
a procurar_verbete.
Em uma boa abstração, gostaríamos de acessar a definição associada ao verbete sem nos preocupar com a forma com que ele é representado. Uma estratégia bastante comum em Python é criar um dicionário que representa um registro de uma coleção de dados. Assim, ao invés de utilizar uma tupla, representamos um verbete por um dicionário como no exemplo
verbete = { "palavra": "amor", "classe": "substantivo", "definicao": "ferida que dói e não se sente", "ano": 1595, }
Vamos adaptar, mais uma vez, o nosso programa.
def criar_dicionario(): """cria um dicionário vazio""" return [] def adicionar_verbete(dicionario, verbete): """adiciona um novo verbete ao dicionário""" i = procurar_indice(dicionario, verbete["palavra"]) if i is None: dicionario.append(verbete) else: raise Exception(f"Palavra {verbete['palavra']} já existe.") def procurar_verbete(dicionario, palavra): """devolve o verbete correspondente à palavra; se palavra não for encontrada, devolve None""" for verbete in dicionario: if verbete["palavra"] == palavra: return verbete return None def procurar_indice(dicionario, palavra): """devolve o índice correspondente à palavra ou None se ela não existir no dicionário""" for i, verbete in enumerate(dicionario): if verbete["palavra"] == palavra: return i return None def atualizar_definicao(dicionario, palavra, nova_definicao): """atualiza a definição de uma palavra""" i = procurar_indice(dicionario, palavra) verbete = dicionario[i] verbete["definicao"] = nova_definicao def main(): dicionario = criar_dicionario() verbete = { "palavra": "amor", "classe": "substantivo", "definicao": "fogo que arde sem se ver", "ano": 1595, } adicionar_verbete(dicionario, verbete) verbete = procurar_verbete(dicionario, "amor") print(f"{verbete['palavra']} significa {verbete['definicao']}") nova_definicao = input("O que você acha que é o amor?\n") atualizar_definicao(dicionario, "amor", nova_definicao) verbete = procurar_verbete(dicionario, "amor") print(f"{verbete['palavra']} agora significa {verbete['definicao']}") main()
Você deve comparar essa implementação com a anterior e decidir qual é
mais fácil de ler e entender. Se compararmos com atenção, no entanto,
vamos ver que a maneira que implementamos alterar_definicao na
versão com dicionários é ligeiramente diferente da maneira que
implementamos essa mesma função na versão com lista. Antes, como não
podíamos alterar os dados de uma tupla, criamos um novo verbete e
substituímos o verbete antigo pelo novo. Agora, apenas alteramos o
verbete diretamente.
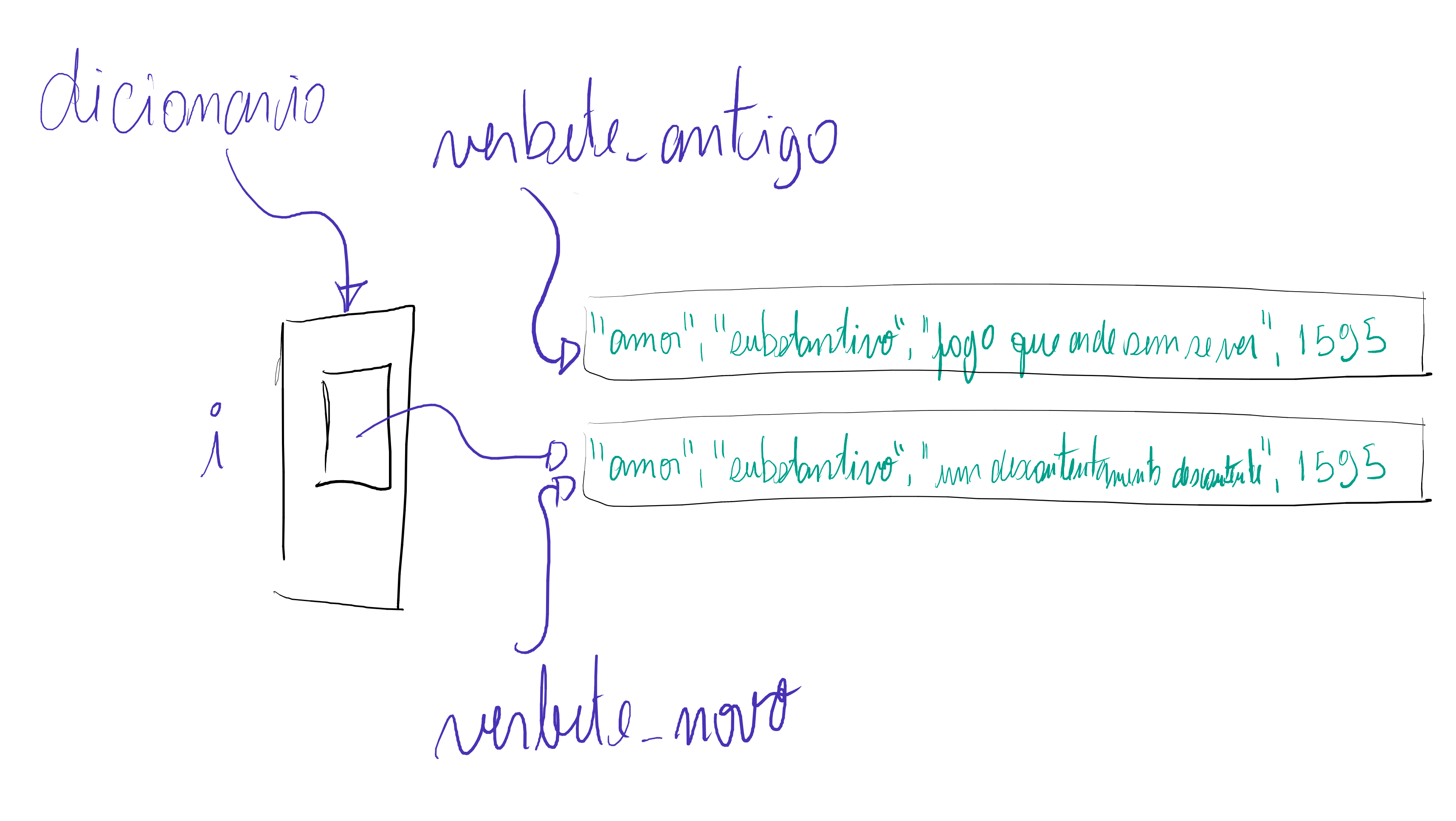
Vamos investigar as consequências disso. Primeiro vamos executar o seguinte trecho de código, utilizando a representação de nossa coleção de verbetes como uma lista de tuplas.
def main(): dicionario = criar_dicionario() anterior = ("amor", "substantivo", "fogo que arde sem se ver", 1595) adicionar_verbete(dicionario, anterior) atualizar_definicao(dicionario, "amor", "um contentamento descontente") atual = procurar_verbete(dicionario, "amor") print(f"antes, amor era {anterior[2]}") print(f"agora, amor é {atual[2]}")
user@notebook:~/ra123456/colecoes$ python3 dicionario_tuplas.py antes, amor era fogo que arde sem se ver agora, amor é um contentamento descontente
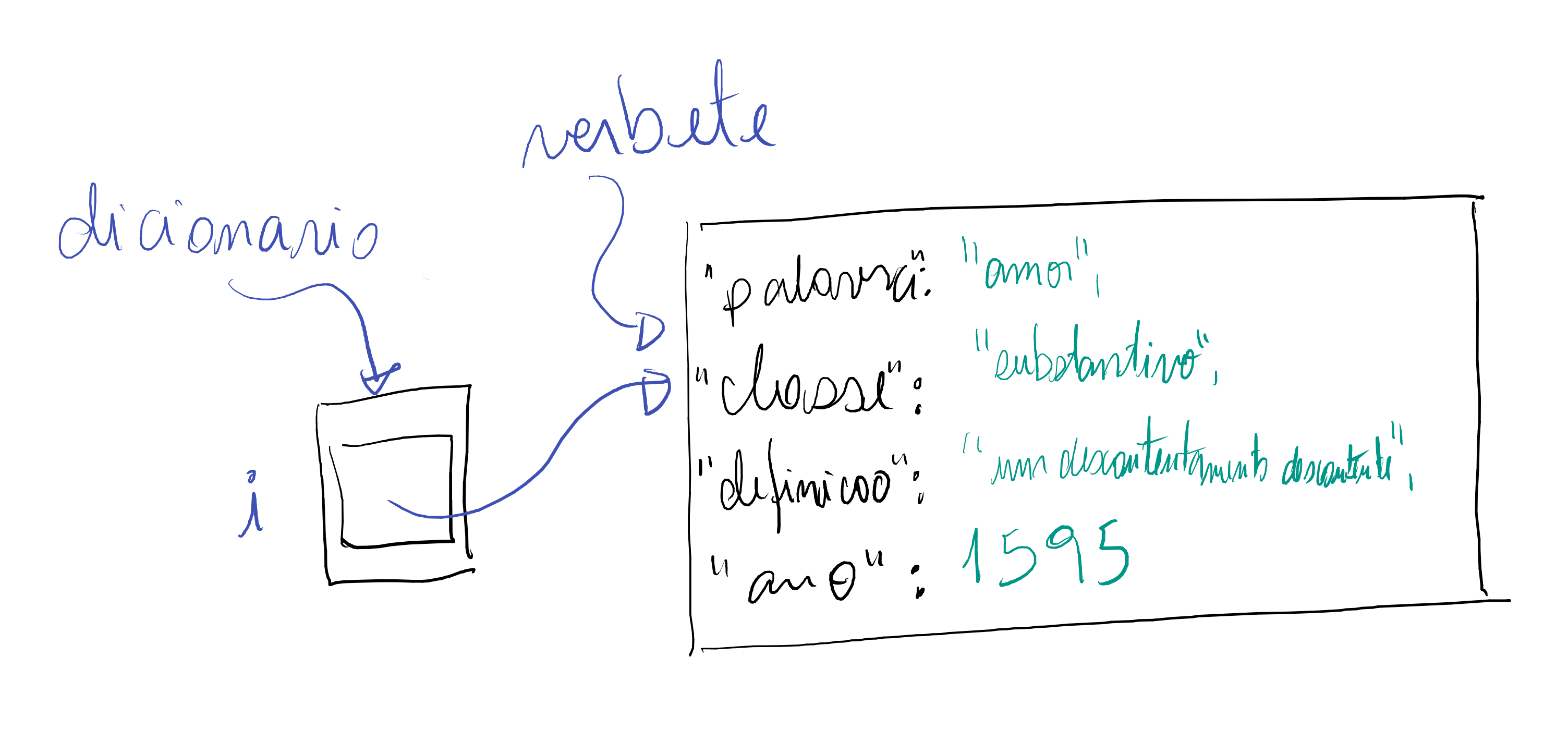
Tudo dentro do esperado. Vamos utilizar a implementação com dicionário.
def main(): dicionario = criar_dicionario() anterior = { "palavra": "amor", "classe": "substantivo", "definicao": "fogo que arde sem se ver", "ano": 1595, } adicionar_verbete(dicionario, anterior) atualizar_definicao(dicionario, "amor", "um contentamento descontente") atual = procurar_verbete(dicionario, "amor") print(f"antes, amor era {anterior['definicao']}") print(f"agora, amor é {atual['definicao']}")
user@notebook:~/ra123456/colecoes$ python3 dicionario_dict.py antes, amor era um contentamento descontente agora, amor é um contentamento descontente
A definição do verbete anterior é a mesma do verbete atual! Isso
acontece porque o verbete alterado atualizar_definicao é o mesmo
verbete adicionado anteriormente. Em outras palavras, anterior e
atual são o mesmo objeto.
Vamos fazer um desenho da memória das variáveis desses programas no
momento em que a função atualizar_definicao termina. Lembre-se de
que, nos nossos desenhos, costumamos representar os valores das
variáveis por retângulos, então cada retângulo corresponde a um objeto
distinto. Para a implementação que usa lista de tuplas, temos o
seguinte desenho.
E para a implementação que usa lista de dicionário, o seguinte.
Para entender a diferença, precisamos aprender o conceito de identidade. Já falamos que toda variável em Python é um objeto na memória com determinado tipo e, normalmente, referenciado pelo nome de uma variável. A identidade de um objeto é um número inteiro associado a esse objeto e a nenhum outro. Podemos pensar que cada objeto é um pequeno espaço reservado na memória. Assim, se dois objetos tiverem a mesma identidade, eles são os mesmos objetos.
Para verificar se dois objetos são o mesmo, utilizamos o operador
is. Para descobrir a identidade de um objeto, utilizamos a função
id. Experimente adicionar o trecho abaixo às funções acima e
executar com cada implementação. Depois faça alterações no código e
experimente até internalizar esses conceitos. Por exemplo, chame a
função atualizar_definicao passando como parâmetro a definição
original.
if atual == anterior: print("objetos são iguais") else: print("objetos são diferentes") if atual is anterior: print("atual e anterior são o mesmo objeto") else: print("atual e anterior são objetos distintos") print(f"o identificador de anterior é {id(anterior)}") print(f"o identificador de atual é {id(atual)}")
Esses exemplos ilustram bem um conceito fundamental em Python e de linguagens de programação em geral: mutabilidade. Um tipo de variável é imutável se um objeto desse tipo não muda nunca.
São exemplos de tipos imutáveis: int, str, tuple. Você pode
desconfiar dessa afirmação, afinal de conta, inúmeras vezes já
escrevemos programas que modificam variáveis inteiras. Por exemplo,
para calcular o dobro de um número podemos escrever.
n = int(input()) n = 2 * n print(f"O dobro é {n}")
Lembremos: quando fazemos uma atribuição, primeiro calculamos o valor
da expressão do lado direito do = e depois associamos o nome a
esquerda a esse valor. Portanto, quando escrevemos n = 2 * n
(leia-se, n recebe 2 * n), o que estamos fazendo é substituir o
valor referenciado pelo seu dobro. Isso pode ser ilustrado pela figura
abaixo.
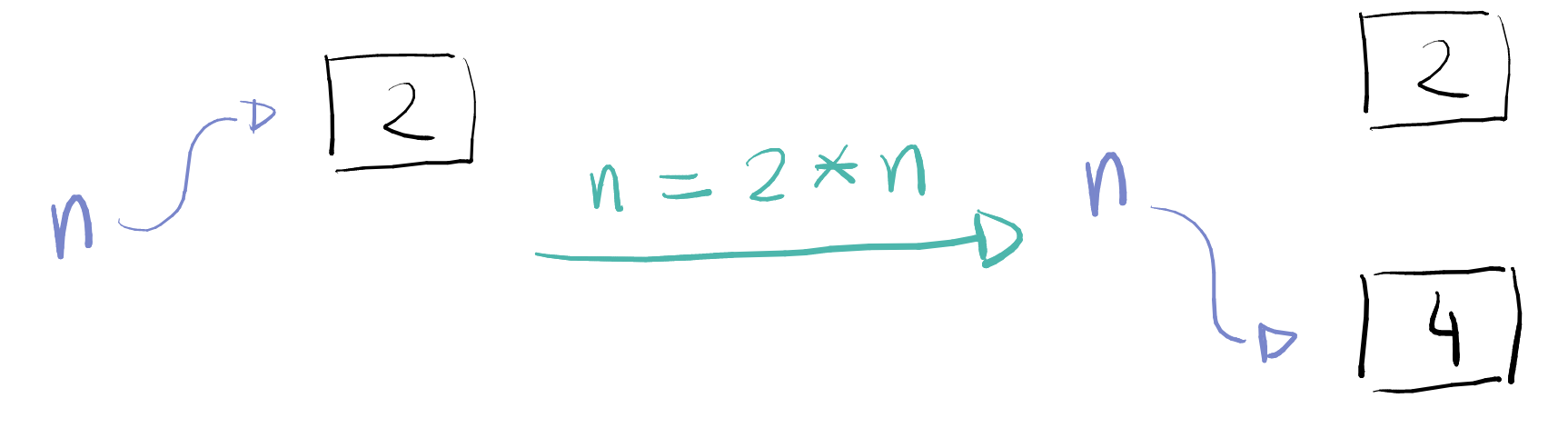
São exemplos de tipos mutáveis list e dict. Devemos tomar cuidado:
quando dizemos que uma lista é mutável, estamos falando que estamos
alterando o objeto correspondente à lista. Se fizermos uma atribuição,
então, estaremos alterando a referência do nome, não o objeto.
Considere o exemplo que mostra duas maneiras distintas de ordenar uma
lista em Python.
lista_strings = ["ana", "maria", "beto"] apelido_lista_strings = lista_strings lista_inteiros = [3, 4, 2, 1] apelido_lista_inteiros = lista_strings lista_strings.sort() lista_inteiros = sorted(lista_inteiros) print(apelido_lista_strings) print(apelido_lista_inteiros)
Descubra qual é a saída deste trecho. Para isso, faça um desenho que representa a memória do processo. Depois, confira sua resposta simulando esse código no terminal interativo do Python.
Um parêntese: JSON
Normalmente, não guardamos os dados diretamente no código de um programa. Para armazená-los permanentemente podemos utilizar diferentes mecanismos, como banco de dados, arquivos binários ou arquivos texto. A escolha depende da aplicação. Em diversas situações, quando a quantidade de dados não é tão grande e queremos apenas consultar os dados, podemos usar um arquivo JSON. Um arquivo JSON é um formato estruturado de guardar conjuntos de dados bastante popular na internet. A grande vantagem desse formato (e de outros similares, como XML, Yaml, Toml etc.) é que ele se mapeia muito facilmente com as representações de coleções de dados que normalmente utilizamos em nossos programa. Depois, não deixe de fazer o exercício de fixação correspondente.
Classes
Um aviso: Você não precisa criar ou usar classes nesta disciplina, mas eventualmente precisará lidar com elas quando estiver trabalhando com Python. Aqui, iremos utilizar classes apenas como meio para guardar um conjunto de dados associados, assim como fizemos com tuplas e dicionários. Há diversas outros motivos pelos quais se usa uma classe, mas não vamos colocar o carro na frente dos bois.
Suponha que o dicionarista decida adicionar mais uma palavra ao dicionário.
verbete = { "palavra": "liberdade", "definicao": "palava que o sonho humano alimenta", "ano": 1953, } adicionar_verbete(dicionario, anterior)
Este trecho é inofensivo e quando executado não irá causar nenhum
erro, mas ele tem um problema de consistência. Um verbete deveria ter
todos as chaves "palavra", "classe", "definicao" e "ano", mas
esquecemos de "classe". Esse é um tipo de erro muito comum que
aconteceu porque, quando criamos o verbete, precisamos nos preocupar
com os detalhes de como ele é representado na memória. Para evitar
esse tipo de problema, podemos criar uma função cujo único objetivo é
criar um verbete. Assim, se esquecermos de algum dado, identificaremos
o erro, antes mesmo de executarmos o programa.
def criar_verbete(palavra, classe, definicao, ano): verbete = { "palavra": palavra, "classe": classe, "definicao": definicao, "ano": ano, } return verbete
Quando representamos um verbete usando um dicionário, estamos fazendo uma abstração nova, mas não estamos criando um novo tipo de variável. O problema de usar um dicionário diretamente é que, se não formos cuidados, podemos acaber realizando operações sobre o objeto de forma a deixar a representação inconsistente. Para abstrações simples como essa, um dicionário é suficiente. Mas, para abstrações mais complicadas precisamos criar um novo tipo de variável. Em Python, fazemos isso usando usamos classes.
Em seguida, criamos uma classe que representa um verbete e uma função
main que cria um objeto desse novo tipo.
class Verbete: def __init__(self, palavra, classe, definicao, ano): self.palavra = palavra self.classe = classe self.definicao = definicao self.ano = ano def main(): verbete = Verbete("amor", "substantivo", "estar-se preso por vontade", 1595) print(f"amor significa {verbete.definicao}") print(type(objeto))
Há vários detalhes aqui que precisamos entender. Primeiro, observe que chamamos o nome da classe como se ela fosse uma função. Quando essa instrução é executada, o que acontece é o seguinte:
- O interpretador Python cria um novo objeto na memória do tipo
Verbete. - A função
Verbete.__init__é chamada para inicializar esse objeto. O primeiro parâmetro deve serselfe corresponde ao objeto recém criado. Os demais parâmetros são os parâmetros passados na chamadaVerbete(...). - A função é executada e cria os diversos atributos contendo os dados associados ao verbete.
Além dos atributos, uma classe pode definir funções que operam sobre o objeto. Por exemplo, digamos que classificamos uma palavra como neologismo se ela for catalogada a partir de certo ano.
class Verbete: def __init__(self, palavra, classe, definicao, ano): self.palavra = palavra self.classe = classe self.definicao = definicao self.ano = ano def eh_neologismo(self): if self.ano >= 1990: return True else: return False def main(): verbete = Verbete("smartphone", "substantivo", "um telefone, só que mais caro", 1997) if verbete.eh_neologismo(): print("a palavra é um neologismo") else: print("a palavra não é um neologismo")
Enquanto o termo classe possa ser uma novidade, já estamos lidando com
elas há muito tempo. Todos os valores em Python são objetos de alguma
classe! Por exemplos, listas são objetos da classe list.
lista1 = [] lista2 = list()
O trecho acima cria dois objetos do tipo list. A expressão [] nada
mais é do que um atalho para uma chamada list(). Quando usamos o
nome de um tipo como se fosse uma função, reservamos um espaço na
memória para um novo objeto. Esse espaço é preenchido por uma função
especial de inicialização; nesse caso, list.__init__.
Agora, modifique nosso programa para que a coleção de verbetes seja
representada como uma lista de objetos do tipo Verbete. Isso não
deve ser difícil, basta mudar expressões como verbete["palavra"]
para expressões como verbete.palavra.
Alternativas
Adicionar um tipo novo parece trivial, mas se feito sem cuidado pode
complicar o nosso programa e prejudicar o entendimento ou a execução
de nosso algoritmo. Se tudo o que queremos é acessar os dados de uma
tupla através de um nome, então poderíamos usar uma
namedtuple,
ou se precisarmos de um objeto mutável, um
SimpleNamespace.
Não vamos estudar todos os tipos da linguagem, nem é necessário para a
disciplina. Mas é sempre bom saber que eles existem.
Finalmente, nossa abstração do dicionário de palavras representado como uma lista sofre dos mesmos problemas que nossa primeira versão da função para calcular um histograma. A solução deve ser clara agora: utilizar uma estrutura de dados mais adequada. Dessa vez, vou deixar para você fazer — ainda mais uma — implementação do dicionário.